Introduction
As the blog was a bit silent for quite some time, I figured it would be cool to put together a post ; so here it is folks, dig in!
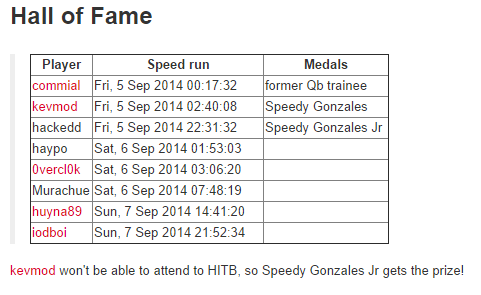
The French company Quarkslab recently released a security challenge to win a free entrance to attend the upcoming HITBSecConf conference in Kuala Lumpur from the 13th of October until the 16th.
The challenge has been written by Serge Guelton, a R&D engineer specialized in compilers/parallel computations. At the time of writing, already eight different people manage to solve the challenge, and one of the ticket seems to have been won by hackedd, so congrats to him!
- first because I already had the occasion to look at its source code in the past,
- and because I so am a big fan of Python.
In this post I will describe how I tackled this problem, how I managed to solve it. And to make up for me being slow at solving it I tried to make it fairly detailed.
At first it was supposed to be quite short though, but well..I decided to analyze fully the challenge even if it wasn't needed to find the key unfortunately, so it is a bit longer than expected :-).
Anyway, sit down, make yourself at home and let me pour you a cup of tea before we begin :-).
Finding the URL of the challenge
Very one-liner, much lambdas, such a pain
The first part of the challenge is to retrieve an url hidden in the following Python one-liner:
(lambda g, c, d: (lambda _: (_.__setitem__('$', ''.join([(_['chr'] if ('chr'
in _) else chr)((_['_'] if ('_' in _) else _)) for _['_'] in (_['s'] if ('s'
in _) else s)[::(-1)]])), _)[-1])( (lambda _: (lambda f, _: f(f, _))((lambda
__,_: ((lambda _: __(__, _))((lambda _: (_.__setitem__('i', ((_['i'] if ('i'
in _) else i) + 1)),_)[(-1)])((lambda _: (_.__setitem__('s',((_['s'] if ('s'
in _) else s) + [((_['l'] if ('l' in _) else l)[(_['i'] if ('i' in _) else i
)] ^ (_['c'] if ('c' in _) else c))])), _)[-1])(_))) if (((_['g'] if ('g' in
_) else g) % 4) and ((_['i'] if ('i' in _) else i)< (_['len'] if ('len' in _
) else len)((_['l'] if ('l' in _) else l)))) else _)), _) ) ( (lambda _: (_.
__setitem__('!', []), _.__setitem__('s', _['!']), _)[(-1)] ) ((lambda _: (_.
__setitem__('!', ((_['d'] if ('d' in _) else d) ^ (_['d'] if ('d' in _) else
d))), _.__setitem__('i', _['!']), _)[(-1)])((lambda _: (_.__setitem__('!', [
(_['j'] if ('j' in _) else j) for _[ 'i'] in (_['zip'] if ('zip' in _) else
zip)((_['l0'] if ('l0' in _) else l0), (_['l1'] if ('l1' in _) else l1)) for
_['j'] in (_['i'] if ('i' in _) else i)]), _.__setitem__('l', _['!']), _)[-1
])((lambda _: (_.__setitem__('!', [1373, 1281, 1288, 1373, 1290, 1294, 1375,
1371,1289, 1281, 1280, 1293, 1289, 1280, 1373, 1294, 1289, 1280, 1372, 1288,
1375,1375, 1289, 1373, 1290, 1281, 1294, 1302, 1372, 1355, 1366, 1372, 1302,
1360, 1368, 1354, 1364, 1370, 1371, 1365, 1362, 1368, 1352, 1374, 1365, 1302
]), _.__setitem__('l1',_['!']), _)[-1])((lambda _: (_.__setitem__('!',[1375,
1368, 1294, 1293, 1373, 1295, 1290, 1373, 1290, 1293, 1280, 1368, 1368,1294,
1293, 1368, 1372, 1292, 1290, 1291, 1371, 1375, 1280, 1372, 1281, 1293,1373,
1371, 1354, 1370, 1356, 1354, 1355, 1370, 1357, 1357, 1302, 1366, 1303,1368,
1354, 1355, 1356, 1303, 1366, 1371]), _.__setitem__('l0', _['!']), _)[(-1)])
({ 'g': g, 'c': c, 'd': d, '$': None})))))))['$'])
I think that was the first time I was seeing obfuscated Python and believe me I did a really strange face when seeing that snippet. But well, with a bit of patience we should manage to get a better understanding of how it is working, let's get to it!
Tidying up the last one..
Before doing that here are things we can directly observe just by looking closely at the snippet:
- We know this function has three arguments ; we don't know them at this point though
- The snippet seems to reuse __setitem__ quite a lot ; it may mean two things for us:
- The only standard Python object I know of with a __setitem__ function is dictionary,
- The way the snippet looks like, it seems that once we will understand one of those __setitem__ call, we will understand them all
- The following standard functions are used: chr, len, zip
- That means manipulation of strings, integers and iterables
- There are two noticeable operators: mod and xor
With all that information in our sleeve, the first thing I did was to try to clean it up, starting from the last lambda in the snippet. It gives something like:
tab0 = [
1375, 1368, 1294, 1293, 1373, 1295, 1290, 1373, 1290, 1293,
1280, 1368, 1368, 1294, 1293, 1368, 1372, 1292, 1290, 1291,
1371, 1375, 1280, 1372, 1281, 1293, 1373, 1371, 1354, 1370,
1356, 1354, 1355, 1370, 1357, 1357, 1302, 1366, 1303, 1368,
1354, 1355, 1356, 1303, 1366, 1371
]
z = lambda x: (
x.__setitem__('!', tab0),
x.__setitem__('l0', x['!']),
x
)[-1]
That lambda takes a dictionary x, sets two items, generates a tuple with a reference to the dictionary at the end of the tuple ; finally the lambda is going to return that same dictionary. It also uses x['!'] as a temporary variable to then assign its value to x['l0'].
Long story short, it basically takes a dictionary, updates it and returns it to the caller: clever trick to pass that same object across lambdas. We can also see that easily in Python directly:
In [8]: d = {}
In [9]: z(d)
Out[9]:
{'!': [1375,
...
'l0': [1375,
...
}
That lambda is even called with a dictionary that will contain, among other things, the three user controlled variable: g, c, d. That dictionary seems to be some kind of storage used to keep track of all the variables that will be used across those lambdas.
# Returns { 'g' : g, 'c', 'd': d, '$':None, '!':tab0, 'l0':tab0}
last_res = (
(
lambda x: (
x.__setitem__('!', tab0),
x.__setitem__('l0', x['!']),
x
)[-1]
)
({ 'g': g, 'c': c, 'd': d, '$': None})
)
..then the one before...
Now if we repeat that same operation with the one before the last lambda, we have the exact same pattern:
tab1 = [
1373, 1281, 1288, 1373, 1290, 1294, 1375, 1371, 1289, 1281,
1280, 1293, 1289, 1280, 1373, 1294, 1289, 1280, 1372, 1288,
1375, 1375, 1289, 1373, 1290, 1281, 1294, 1302, 1372, 1355,
1366, 1372, 1302, 1360, 1368, 1354, 1364, 1370, 1371, 1365,
1362, 1368, 1352, 1374, 1365, 1302
]
zz = lambda x: (
x.__setitem__('!', tab1),
x.__setitem__('l1', x['!']),
x
)[-1]
Perfect, now let's repeat the same operations over and over again. At some point, the whole thing becomes crystal clear (sort-of):
# Returns {
# 'g':g, 'c':c, 'd':d,
# '!':[],
# 's':[],
# 'l':[j for i in zip(tab0, tab1) for j in i],
# 'l1':tab1,
# 'l0':tab0,
# 'i': 0,
# 'j': 1302,
# '$':None
#}
res_after_all_operations = (
(
lambda x: (
x.__setitem__('!', []),
x.__setitem__('s', x['!']),
x
)[-1]
)
# ..
(
(
lambda x: (
x.__setitem__('!', ((x['d'] if ('d' in x) else d) ^ (x['d'] if ('d' in x) else d))),
x.__setitem__('i', x['!']),
x
)[-1]
)
# ..
(
(
lambda x: (
x.__setitem__('!', [(x['j'] if ('j' in x) else j) for x[ 'i'] in (x['zip'] if ('zip' in x) else zip)((x['l0'] if ('l0' in x) else l0), (x['l1'] if ('l1' in x) else l1)) for x['j'] in (x['i'] if ('i' in x) else i)]),
x.__setitem__('l', x['!']),
x
)[-1]
)
# Returns { 'g':g, 'c':c, 'd':d, '!':tab1, 'l1':tab1, 'l0':tab0, '$':None}
(
(
lambda x: (
x.__setitem__('!', tab1),
x.__setitem__('l1', x['!']),
x
)[-1]
)
# Return { 'g' : g, 'c', 'd': d, '!':tab0, 'l0':tab0, '$':None }
(
(
lambda x: (
x.__setitem__('!', tab0),
x.__setitem__('l0', x['!']),
x
)[-1]
)
({ 'g': g, 'c': c, 'd': d, '$': None})
)
)
)
)
)
Putting it all together
After doing all of that, we know now the types of the three variables the function needs to work properly (and we don't really need more to be honest):
- g is an integer that will be mod 4
- if the value is divisible by 4, the function returns nothing ; so we will need to have this variable sets to 1 for example
- c is another integer that looks like a xor key ; if we look at the snippet, this variable is used to xor each byte of x['l'] (which is the table with tab0 and tab1)
- this is the interesting parameter
- d is another integer that we can also ignore: it's only used to set x['i'] to zero by xoring x['d'] by itself.
We don't need anything else really now: no more lambdas, no more pain, no more tears. It is time to write what I call, an educated brute-forcer, to find the correct value of c:
import sys
def main(argc, argv):
tab0 = [1375, 1368, 1294, 1293, 1373, 1295, 1290, 1373, 1290, 1293, 1280, 1368, 1368,1294, 1293, 1368, 1372, 1292, 1290, 1291, 1371, 1375, 1280, 1372, 1281, 1293,1373, 1371, 1354, 1370, 1356, 1354, 1355, 1370, 1357, 1357, 1302, 1366, 1303,1368, 1354, 1355, 1356, 1303, 1366, 1371]
tab1 = [1373, 1281, 1288, 1373, 1290, 1294, 1375, 1371,1289, 1281, 1280, 1293, 1289, 1280, 1373, 1294, 1289, 1280, 1372, 1288, 1375,1375, 1289, 1373, 1290, 1281, 1294, 1302, 1372, 1355, 1366, 1372, 1302, 1360, 1368, 1354, 1364, 1370, 1371, 1365, 1362, 1368, 1352, 1374, 1365, 1302]
func = (
lambda g, c, d:
(
lambda x: (
x.__setitem__('$', ''.join([(x['chr'] if ('chr' in x) else chr)((x['_'] if ('_' in x) else x)) for x['_'] in (x['s'] if ('s' in x) else s)[::-1]])),
x
)[-1]
)
(
(
lambda x:
(lambda f, x: f(f, x))
(
(
lambda __, x:
(
(lambda x: __(__, x))
(
# i += 1
(
lambda x: (
x.__setitem__('i', ((x['i'] if ('i' in x) else i) + 1)),
x
)[-1]
)
(
# s += [c ^ l[i]]
(
lambda x: (
x.__setitem__('s', (
(x['s'] if ('s' in x) else s) +
[((x['l'] if ('l' in x) else l)[(x['i'] if ('i' in x) else i)] ^ (x['c'] if ('c' in x) else c))]
)
),
x
)[-1]
)
(x)
)
)
# if ((x['g'] % 4) and (x['i'] < len(l))) else x
if (((x['g'] if ('g' in x) else g) % 4) and ((x['i'] if ('i' in x) else i)< (x['len'] if ('len' in x) else len)((x['l'] if ('l' in x) else l))))
else x
)
),
x
)
)
# Returns { 'g':g, 'c':c, 'd':d, '!':zip(tab1, tab0), 'l':zip(tab1, tab0), l1':tab1, 'l0':tab0, 'i': 0, 'j': 1302, '!':0, 's':[] }
(
(
lambda x: (
x.__setitem__('!', []),
x.__setitem__('s', x['!']),
x
)[-1]
)
# Returns { 'g':g, 'c':c, 'd':d, '!':zip(tab1, tab0), 'l':zip(tab1, tab0), l1':tab1, 'l0':tab0, 'i': 0, 'j': 1302, '!':0}
(
(
lambda x: (
x.__setitem__('!', ((x['d'] if ('d' in x) else d) ^ (x['d'] if ('d' in x) else d))),
x.__setitem__('i', x['!']),
x
)[-1]
)
# Returns { 'g' : g, 'c', 'd': d, '!':zip(tab1, tab0), 'l':zip(tab1, tab0), l1':tab1, 'l0':tab0, 'i': (1371, 1302), 'j': 1302}
(
(
lambda x: (
x.__setitem__('!', [(x['j'] if ('j' in x) else j) for x[ 'i'] in (x['zip'] if ('zip' in x) else zip)((x['l0'] if ('l0' in x) else l0), (x['l1'] if ('l1' in x) else l1)) for x['j'] in (x['i'] if ('i' in x) else i)]),
x.__setitem__('l', x['!']),
x
)[-1]
)
# Returns { 'g' : g, 'c', 'd': d, '!':tab1, 'l1':tab1, 'l0':tab0}
(
(
lambda x: (
x.__setitem__('!', tab1),
x.__setitem__('l1', x['!']),
x
)[-1]
)
# Return { 'g' : g, 'c', 'd': d, '!' : tab0, 'l0':tab0}
(
(
lambda x: (
x.__setitem__('!', tab0),
x.__setitem__('l0', x['!']),
x
)[-1]
)
({ 'g': g, 'c': c, 'd': d, '$': None})
)
)
)
)
)
)['$']
)
for i in range(0x1000):
try:
ret = func(1, i, 0)
if 'quarks' in ret:
print ret
except:
pass
return 1
if __name__ == '__main__':
sys.exit(main(len(sys.argv), sys.argv))
And after running it, we are good to go:
D:\Codes\challenges\ql-python>bf_with_lambdas_cleaned.py
/blog.quarkslab.com/static/resources/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
A custom ELF64 Python interpreter you shall debug
Recon
All right, here we are: we now have the real challenge. First, let's see what kind of information we get for free:
overclok@wildout:~/chall/ql-py$ file b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs),
for GNU/Linux 2.6.26, not stripped
overclok@wildout:~/chall/ql-py$ ls -lah b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
-rwxrw-r-x 1 overclok overclok 7.9M Sep 8 21:03 b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
The binary is quite big, not good for us. But on the other hand, the binary isn't stripped so we might find useful debugging information at some point.
overclok@wildout:~/chall/ql-py$ /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
Python 2.7.8+ (nvcs/newopcodes:a9bd62e4d5f2+, Sep 1 2014, 11:41:46)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
That does explain the size of the binary then: we basically have something that looks like a custom Python interpreter. Note that I also remembered reading Building an obfuscated Python interpreter: we need more opcodes on Quarkslab's blog where Serge described how you could tweak the interpreter sources to add / change some opcodes either for optimization or obfuscation purposes.
Finding the interesting bits
The next step is to figure out what part of the binary is interesting, what functions have been modified, and where we find the problem we need to solve to get the flag. My idea for that was to use a binary-diffing tool between an original Python278 interpreter and the one we were given.
To do so I just grabbed Python278's sources and compiled them by myself:
overclok@wildout:~/chall/ql-py$ wget https://www.python.org/ftp/python/2.7.8/Python-2.7.8.tgz && tar xzvf Python-2.7.8.tgz
overclok@wildout:~/chall/ql-py$ tar xzvf Python-2.7.8.tgz
overclok@wildout:~/chall/ql-py$ cd Python-2.7.8/ && ./configure && make
overclok@wildout:~/chall/ql-py/Python-2.7.8$ ls -lah ./python
-rwxrwxr-x 1 overclok overclok 8.0M Sep 5 00:13 ./python
The resulting binary has a similar size, so it should do the job even if I'm not using GCC 4.8.2 and the same compilation/optimization options. To perform the diffing I used IDA Pro and Patchdiff v2.0.10.
---------------------------------------------------
PatchDiff Plugin v2.0.10
Copyright (c) 2010-2011, Nicolas Pouvesle
Copyright (C) 2007-2009, Tenable Network Security, Inc
---------------------------------------------------
Scanning for functions ...
parsing second idb...
parsing first idb...
diffing...
Identical functions: 2750
Matched functions: 176
Unmatched functions 1: 23
Unmatched functions 2: 85
done!
Once the tool has finished its analysis we just have to check the list of unmatched function names (around one hundred of them, so it's pretty quick), and eventually we see that:

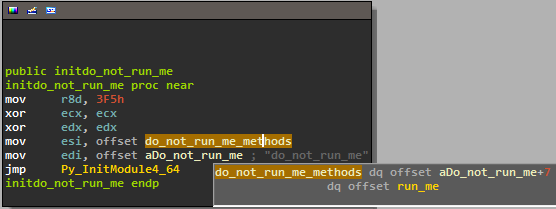
overclok@wildout:~/chall/ql-py$ /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
iPython 2.7.8+ (nvcs/newopcodes:a9bd62e4d5f2+, Sep 1 2014, 11:41:46)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import do_not_run_me
>>> print do_not_run_me.__doc__
None
>>> dir(do_not_run_me)
['__doc__', '__name__', '__package__', 'run_me']
>>> print do_not_run_me.run_me.__doc__
There are two kinds of people in the world: those who say there is no such thing as infinite recursion, and those who say ``There are two kinds of people in the world: those who say there is no such thing as infinite recursion, and those who say ...
>>> do_not_run_me.run_me('doar-e')
Segmentation fault
All right, we now have something to look at and we are going to do so from a low level point of view because that's what I like ; so don't expect big/magic hacks here :).
If you are not really familiar with Python's VM structures I would advise you to read quickly through this article Deep Dive Into Python’s VM: Story of LOAD_CONST Bug, and you should be all set for the next parts.
do_not_run_me.run_me
The function is quite small, so it should be pretty quick to analyze:
- the first part makes sure that we pass a string as an argument when calling run_me,
- then a custom marshaled function is loaded, a function is created out of it, and called,
- after that it creates another function from the string we pass to the function (which explains the segfault just above),
- finally, a last function is created from another hardcoded marshaled string.
First marshaled function
To understand it we have to dump it first, to unmarshal it and to analyze the resulting code object:
overclok@wildout:~/chall/ql-py$ gdb -q /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
Reading symbols from /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf...done.
gdb$ set disassembly-flavor intel
gdb$ disass run_me
Dump of assembler code for function run_me:
0x0000000000513d90 <+0>: push rbp
0x0000000000513d91 <+1>: mov rdi,rsi
0x0000000000513d94 <+4>: xor eax,eax
0x0000000000513d96 <+6>: mov esi,0x56c70b
0x0000000000513d9b <+11>: push rbx
0x0000000000513d9c <+12>: sub rsp,0x28
0x0000000000513da0 <+16>: lea rcx,[rsp+0x10]
0x0000000000513da5 <+21>: mov rdx,rsp
; Parses the arguments we gave, it expects a string object
0x0000000000513da8 <+24>: call 0x4cf430 <PyArg_ParseTuple>
0x0000000000513dad <+29>: xor edx,edx
0x0000000000513daf <+31>: test eax,eax
0x0000000000513db1 <+33>: je 0x513e5e <run_me+206>
0x0000000000513db7 <+39>: mov rax,QWORD PTR [rip+0x2d4342]
0x0000000000513dbe <+46>: mov esi,0x91
0x0000000000513dc3 <+51>: mov edi,0x56c940
0x0000000000513dc8 <+56>: mov rax,QWORD PTR [rax+0x10]
0x0000000000513dcc <+60>: mov rbx,QWORD PTR [rax+0x30]
; Creates a code object from the marshaled string
; PyObject* PyMarshal_ReadObjectFromString(char *string, Py_ssize_t len)
0x0000000000513dd0 <+64>: call 0x4dc020 <PyMarshal_ReadObjectFromString>
0x0000000000513dd5 <+69>: mov rdi,rax
0x0000000000513dd8 <+72>: mov rsi,rbx
; Creates a function object from the marshaled string
0x0000000000513ddb <+75>: call 0x52c630 <PyFunction_New>
0x0000000000513de0 <+80>: xor edi,edi
[...]
gdb$ r -c 'import do_not_run_me as v; v.run_me("")'
Starting program: /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf -c 'import do_not_run_me as v; v.run_me("")'
[...]
To start, we can set two software breakpoints @0x0000000000513dd0 and @0x0000000000513dd5 to inspect both the marshaled string and the resulting code object.
Just a little reminder though on the Linux/x64 ABI: "The first six integer or pointer arguments are passed in registers RDI, RSI, RDX, RCX, R8, and R9".
gdb$ p /x $rsi
$2 = 0x91
gdb$ x/145bx $rdi
0x56c940 <+00>: 0x63 0x00 0x00 0x00 0x00 0x01 0x00 0x00
0x56c948 <+08>: 0x00 0x02 0x00 0x00 0x00 0x43 0x00 0x00
0x56c950 <+16>: 0x00 0x73 0x14 0x00 0x00 0x00 0x64 0x01
0x56c958 <+24>: 0x00 0x87 0x00 0x00 0x7c 0x00 0x00 0x64
0x56c960 <+32>: 0x01 0x00 0x3c 0x61 0x00 0x00 0x7c 0x00
0x56c968 <+40>: 0x00 0x1b 0x28 0x02 0x00 0x00 0x00 0x4e
0x56c970 <+48>: 0x69 0x01 0x00 0x00 0x00 0x28 0x01 0x00
0x56c978 <+56>: 0x00 0x00 0x74 0x04 0x00 0x00 0x00 0x54
0x56c980 <+64>: 0x72 0x75 0x65 0x28 0x01 0x00 0x00 0x00
0x56c988 <+72>: 0x74 0x0e 0x00 0x00 0x00 0x52 0x6f 0x62
0x56c990 <+80>: 0x65 0x72 0x74 0x5f 0x46 0x6f 0x72 0x73
0x56c998 <+88>: 0x79 0x74 0x68 0x28 0x00 0x00 0x00 0x00
0x56c9a0 <+96>: 0x28 0x00 0x00 0x00 0x00 0x73 0x10 0x00
0x56c9a8 <+104>: 0x00 0x00 0x6f 0x62 0x66 0x75 0x73 0x63
0x56c9b0 <+112>: 0x61 0x74 0x65 0x2f 0x67 0x65 0x6e 0x2e
0x56c9b8 <+120>: 0x70 0x79 0x74 0x03 0x00 0x00 0x00 0x66
0x56c9c0 <+128>: 0x6f 0x6f 0x05 0x00 0x00 0x00 0x73 0x06
0x56c9c8 <+136>: 0x00 0x00 0x00 0x00 0x01 0x06 0x02 0x0a
0x56c9d0 <+144>: 0x01
And obviously you can't use the Python marshal module to load & inspect the resulting object as the author seems to have removed the methods loads and dumps:
overclok@wildout:~/chall/ql-py$ /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
Python 2.7.8+ (nvcs/newopcodes:a9bd62e4d5f2+, Sep 1 2014, 11:41:46)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import marshal
>>> dir(marshal)
['__doc__', '__name__', '__package__', 'version']
We could still try to run the marshaled string in our fresh compiled original Python though:
>>> import marshal
>>> part_1 = marshal.loads('c\x00\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00C\x00\x00\x00s\x14\x00\x00\x00d\x01\x00\x87\x00\x00|\x00\x00d\x01\x00<a\x00\x00|\x00\x00\x1b(\x02\x00\x00\x00Ni\x01\x00\x00\x00(\x01\x00\x00\x00t\x04\x00\x00\x00True(\x01\x00\x00\x00t\x0e\x00\x00\x00Robert_Forsyth(\x00\x00\x00\x00(\x00\x00\x00\x00s\x10\x00\x00\x00obfuscate/gen.pyt\x03\x00\x00\x00foo\x05\x00\x00\x00s\x06\x00\x00\x00\x00\x01\x06\x02\n\x01')
>>> part_1.co_code
'd\x01\x00\x87\x00\x00|\x00\x00d\x01\x00<a\x00\x00|\x00\x00\x1b'
>>> part_1.co_varnames
('Robert_Forsyth',)
>>> part_1.co_names
('True',)
We can also go further by trying to create a function out of this code object, to call it and/or to disassemble it even:
>>> from types import FunctionType
>>> def a():
... pass
...
>>> f = FunctionType(part_1, a.func_globals)
>>> f()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "obfuscate/gen.py", line 8, in foo
UnboundLocalError: local variable 'Robert_Forsyth' referenced before assignment
>>> import dis
>>> dis.dis(f)
6 0 LOAD_CONST 1 (1)
3 LOAD_CLOSURE 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/overclok/chall/ql-py/Python-2.7.8/Lib/dis.py", line 43, in dis
disassemble(x)
File "/home/overclok/chall/ql-py/Python-2.7.8/Lib/dis.py", line 107, in disassemble
print '(' + free[oparg] + ')',
IndexError: tuple index out of range
Introducing dpy.py
All right, as expected this does not work at all: seems like the custom interpreter uses different opcodes which the original virtual CPU doesn't know about. Anyway, let's have a look at this object directly from memory because we like low level things (remember?):
gdb$ p *(PyObject*)$rax
$3 = {ob_refcnt = 0x1, ob_type = 0x7d3da0 <PyCode_Type>}
; Ok it is a code object, let's dump entirely the object now
gdb$ p *(PyCodeObject*)$rax
$4 = {
ob_refcnt = 0x1,
ob_type = 0x7d3da0 <PyCode_Type>,
co_argcount = 0x0, co_nlocals = 0x1, co_stacksize = 0x2, co_flags = 0x43,
co_code = 0x7ffff7f09df0,
co_consts = 0x7ffff7ee2908,
co_names = 0x7ffff7f8e390,
co_varnames = 0x7ffff7f09ed0,
co_freevars = 0x7ffff7fa7050, co_cellvars = 0x7ffff7fa7050,
co_filename = 0x7ffff70a9b58,
co_name = 0x7ffff7f102b0,
co_firstlineno = 0x5,
co_lnotab = 0x7ffff7e59900,
co_zombieframe = 0x0,
co_weakreflist = 0x0
}
Perfect, and you can do that for every single field of this structure:
- to dump the bytecode,
- the constants used,
- the variable names,
- etc.
Yes, this is annoying, very much so. That is exactly why there is dpy, a GDB Python command I wrote to dump Python objects in a much easy way directly from memory:
gdb$ r
Starting program: /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
[...]
>>> a = { 1 : [1,2,3], 'two' : 31337, 3 : (1,'lul', [3,4,5])}
>>> print hex(id(a))
0x7ffff7ef1050
>>> ^C
Program received signal SIGINT, Interrupt.
gdb$ dpy 0x7ffff7ef1050
dict -> {1: [1, 2, 3], 3: (1, 'lul', [3, 4, 5]), 'two': 31337}
I need a disassembler now dad
But let's get back to our second breakpoint now, and see what dpy gives us with the resulting code object:
gdb$ dpy $rax
code -> {'co_code': 'd\x01\x00\x87\x00\x00|\x00\x00d\x01\x00<a\x00\x00|\x00\x00\x1b',
'co_consts': (None, 1),
'co_name': 'foo',
'co_names': ('True',),
'co_varnames': ('Robert_Forsyth',)}
Because we know the bytecode used by this interpreter is different than the original one, we have to figure out the equivalent between the instructions and their opcodes:
- Either we can reverse-engineer each handler of the virtual CPU,
- Either we can create functions in both interpreters, disassemble those (thanks to dpy) and match the equivalent opcodes
I guess we can mix both of them to be more efficient:
Python 2.7.8 (default, Sep 5 2014, 00:13:07)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> def assi(x):
... x = 'hu'
...
>>> def add(x):
... return x + 31337
...
>>> import dis
>>> dis.dis(assi)
2 0 LOAD_CONST 1 ('hu')
3 STORE_FAST 0 (x)
6 LOAD_CONST 0 (None)
9 RETURN_VALUE
>>> dis.dis(add)
2 0 LOAD_FAST 0 (x)
3 LOAD_CONST 1 (31337)
6 BINARY_ADD
7 RETURN_VALUE
>>> assi.func_code.co_code
'd\x01\x00}\x00\x00d\x00\x00S'
>>> add.func_code.co_code
'|\x00\x00d\x01\x00\x17S'
# In the custom interpreter
gdb$ r
Starting program: /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Python 2.7.8+ (nvcs/newopcodes:a9bd62e4d5f2+, Sep 1 2014, 11:41:46)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> def assi(x):
... x = 'hu'
...
>>> def add(x):
... return x + 31337
...
>>> print hex(id(assi))
0x7ffff7f0c578
>>> print hex(id(add))
0x7ffff7f0c5f0
>>> ^C
Program received signal SIGINT, Interrupt.
gdb$ dpy 0x7ffff7f0c578
function -> {'func_code': {'co_code': 'd\x01\x00\x87\x00\x00d\x00\x00\x1b',
'co_consts': (None, 'hu'),
'co_name': 'assi',
'co_names': (),
'co_varnames': ('x',)},
'func_dict': None,
'func_doc': None,
'func_module': '__main__',
'func_name': 'assi'}
gdb$ dpy 0x7ffff7f0c5f0
function -> {'func_code': {'co_code': '\x8f\x00\x00d\x01\x00=\x1b',
'co_consts': (None, 31337),
'co_name': 'add',
'co_names': (),
'co_varnames': ('x',)},
'func_dict': None,
'func_doc': None,
'func_module': '__main__',
'func_name': 'add'}
# From here we have:
# 0x64 -> LOAD_CONST
# 0x87 -> STORE_FAST
# 0x1b -> RETURN_VALUE
# 0x8f -> LOAD_FAST
# 0x3d -> BINARY_ADD
OK I think you got the idea, and if you don't manage to find all of them you can just debug the virtual CPU by putting a software breakpoint @0x4b0960:
=> 0x4b0923 <PyEval_EvalFrameEx+867>: movzx eax,BYTE PTR [r13+0x0]
For the interested readers: there is at least one interesting opcode that you wouldn't find in a normal Python interpreter, check what 0xA0 is doing especially when followed by 0x87 :-).
Back to the first marshaled function with all our tooling now
Thanks to our disassembler.py, we can now disassemble easily the first part:
PS D:\Codes\ql-chall-python-2014> python .\disassembler_ql_chall.py
6 0 LOAD_CONST 1 (1)
3 STORE_FAST 0 (Robert_Forsyth)
8 6 LOAD_GLOBAL 0 (True)
9 LOAD_CONST 1 (1)
12 INPLACE_ADD
13 STORE_GLOBAL 0 (True)
9 16 LOAD_GLOBAL 0 (True)
19 RETURN_VALUE
================================================================================
It seems the author has been really (too) kind with us: the function is really small and we can rewrite it in Python straightaway:
def part1():
global True
Robert_Forsyth = 1
True += 1
You can also make sure with dpy that the code of part1 is the exact same than the unmarshaled function we dumped earlier.
>>> def part_1():
... global True
... Robert_Forsyth = 1
... True += 1
...
>>> print hex(id(part_1))
0x7ffff7f0f578
>>> ^C
Program received signal SIGINT, Interrupt.
gdb$ dpy 0x7ffff7f0f578
function -> {'func_code': {'co_code': 'd\x01\x00\x87\x00\x00|\x00\x00d\x01\x00<a\x00\x00d\x00\x00\x1b',
'co_consts': (None, 1),
'co_name': 'part_1',
'co_names': ('True',),
'co_varnames': ('Robert_Forsyth',)},
'func_dict': None,
'func_doc': None,
'func_module': '__main__',
'func_name': 'part_1'}
Run my bytecode
The second part is also quite simple according to the following disassembly:
gdb$ disass run_me
Dump of assembler code for function run_me:
[...]
; Parses the arguments we gave, it expects a string object
0x0000000000513da0 <+16>: lea rcx,[rsp+0x10]
0x0000000000513da5 <+21>: mov rdx,rsp
0x0000000000513da8 <+24>: call 0x4cf430 <PyArg_ParseTuple>
0x0000000000513dad <+29>: xor edx,edx
0x0000000000513daf <+31>: test eax,eax
0x0000000000513db1 <+33>: je 0x513e5e <run_me+206>
0x0000000000513db7 <+39>: mov rax,QWORD PTR [rip+0x2d4342]
0x0000000000513dbe <+46>: mov esi,0x91
0x0000000000513dc3 <+51>: mov edi,0x56c940
0x0000000000513dc8 <+56>: mov rax,QWORD PTR [rax+0x10]
0x0000000000513dcc <+60>: mov rbx,QWORD PTR [rax+0x30]
[...]
; Part1
[...]
0x0000000000513df7 <+103>: mov rsi,QWORD PTR [rsp+0x10]
0x0000000000513dfc <+108>: mov rdi,QWORD PTR [rsp]
; Uses the string passed as argument to run_me as a marshaled object
; PyObject* PyMarshal_ReadObjectFromString(char *string, Py_ssize_t len)
0x0000000000513e00 <+112>: call 0x4dc020 <PyMarshal_ReadObjectFromString>
0x0000000000513e05 <+117>: mov rsi,rbx
0x0000000000513e08 <+120>: mov rdi,rax
; Creates a function out of it
0x0000000000513e0b <+123>: call 0x52c630 <PyFunction_New>
0x0000000000513e10 <+128>: xor edi,edi
0x0000000000513e12 <+130>: mov rbp,rax
0x0000000000513e15 <+133>: call 0x478f80 <PyTuple_New>
; Calls it
; PyObject* PyObject_Call(PyObject *callable_object, PyObject *args, PyObject *kw)
0x0000000000513e1a <+138>: xor edx,edx
0x0000000000513e1c <+140>: mov rdi,rbp
0x0000000000513e1f <+143>: mov rsi,rax
0x0000000000513e22 <+146>: call 0x422b40 <PyObject_Call>
Basically, the string you pass to run_me is treated as a marshaled function: it explains why you get segmentation faults when you call the function with random strings. We can just jump over that part of the function because we don't really need it so far: set $eip=0x513e27 and job done!
Second & last marshaled function
By the way I hope you are still reading -- hold tight, we are nearly done! Let's dump the function object with dpy:
-----------------------------------------------------------------------------------------------------------------------[regs]
RAX: 0x00007FFFF7FA7050 RBX: 0x00007FFFF7F0F758 RBP: 0x00000000007B0270 RSP: 0x00007FFFFFFFE040 o d I t s Z a P c
RDI: 0x00007FFFF7F0F758 RSI: 0x00007FFFF7FA7050 RDX: 0x0000000000000000 RCX: 0x0000000000000828 RIP: 0x0000000000513E56
R8 : 0x0000000000880728 R9 : 0x00007FFFF7F8D908 R10: 0x00007FFFF7FA7050 R11: 0x00007FFFF7FA7050 R12: 0x00007FFFF7FD0F48
R13: 0x00000000007EF0A0 R14: 0x00007FFFF7F3CB00 R15: 0x00007FFFF7F07ED0
CS: 0033 DS: 0000 ES: 0000 FS: 0000 GS: 0000 SS: 002B
-----------------------------------------------------------------------------------------------------------------------[code]
=> 0x513e56 <run_me+198>: call 0x422b40 <PyObject_Call>
-----------------------------------------------------------------------------------------------------------------------------
gdb$ dpy $rdi
function -> {'func_code': {'co_code': '\\x7c\\x00\\x00\\x64\\x01\\x00\\x6b\\x03\\x00\\x72\\x19\\x00\\x7c\\x00\\x00\\x64\\x02\\x00\\x55\\x61\\x00\\x00\\x6e\\x6e\\x00\\x7c\\x01\\x00\\x6a\\x02\\x00\\x64\\x03\\x00\\x6a\\x03\\x00\\x64\\x04\\x00\\x77\\x00\\x00\\xa0\\x05\\x00\\xc8\\x06\\x00\\xa0\\x07\\x00\\xb2\\x08\\x00\\xa0\\x09\\x00\\xea\\x0a\\x00\\xa0\\x0b\\x00\\x91\\x08\\x00\\xa0\\x0c\\x00\\x9e\\x0b\\x00\\xa0\\x0d\\x00\\xd4\\x08\\x00\\xa0\\x0e\\x00\\xd5\\x0f\\x00\\xa0\\x10\\x00\\xdd\\x11\\x00\\xa0\\x07\\x00\\xcc\\x08\\x00\\xa0\\x12\\x00\\x78\\x0b\\x00\\xa0\\x13\\x00\\x87\\x0f\\x00\\xa0\\x14\\x00\\x5b\\x15\\x00\\xa0\\x16\\x00\\x97\\x17\\x00\\x67\\x1a\\x00\\x53\\x86\\x01\\x00\\x86\\x01\\x00\\x86\\x01\\x00\\x54\\x64\\x00\\x00\\x1b',
'co_consts': (None,
3,
1,
'',
{'co_code': '\\x8f\\x00\\x00\\x5d\\x15\\x00\\x87\\x01\\x00\\x7c\\x00\\x00\\x8f\\x01\\x00\\x64\\x00\\x00\\x4e\\x86\\x01\\x00\\x59\\x54\\x71\\x03\\x00\\x64\\x01\\x00\\x1b',
'co_consts': (13, None),
'co_name': '<genexpr>',
'co_names': ('chr',),
'co_varnames': ('.0', '_')},
75,
98,
127,
45,
89,
101,
104,
67,
122,
65,
120,
99,
108,
95,
125,
111,
97,
100,
110),
'co_name': 'foo',
'co_names': ('True', 'quarkslab', 'append', 'join'),
'co_varnames': ()},
'func_dict': None,
'func_doc': None,
'func_module': '__main__',
'func_name': 'foo'}
Even before studying / disassembling the code, we see some interesting things: chr, quarkslab, append, join, etc. It definitely feels like that function is generating the flag we are looking for.
Seeing append, join and another code object (in co_consts) suggests that a generator is used to populate the variable quarkslab. We also can guess that the bunch of bytes we are seeing may be the flag encoded/encrypted -- anyway we can infer too much information to me just by dumping/looking at the object.
Let's use our magic disassembler.py to see those codes objects:
19 >> 0 LOAD_GLOBAL 0 (True)
3 LOAD_CONST 1 (3)
6 COMPARE_OP 3 (!=)
9 POP_JUMP_IF_FALSE 25
20 12 LOAD_GLOBAL 0 (True)
15 LOAD_CONST 2 (1)
18 INPLACE_SUBTRACT
19 STORE_GLOBAL 0 (True)
22 JUMP_FORWARD 110 (to 135)
22 >> 25 LOAD_GLOBAL 1 (quarkslab)
28 LOAD_ATTR 2 (append)
31 LOAD_CONST 3 ('')
34 LOAD_ATTR 3 (join)
37 LOAD_CONST 4 (<code object <genexpr> at 023A84A0, file "obfuscate/gen.py", line 22>)
40 MAKE_FUNCTION 0
43 LOAD_CONST2 5 (75)
46 LOAD_CONST3 6 (98)
49 LOAD_CONST2 7 (127)
52 LOAD_CONST5 8 (45)
55 LOAD_CONST2 9 (89)
58 LOAD_CONST4 10 (101)
61 LOAD_CONST2 11 (104)
64 LOAD_CONST6 8 (45)
67 LOAD_CONST2 12 (67)
70 LOAD_CONST7 11 (104)
73 LOAD_CONST2 13 (122)
76 LOAD_CONST8 8 (45)
79 LOAD_CONST2 14 (65)
82 LOAD_CONST10 15 (120)
85 LOAD_CONST2 16 (99)
88 LOAD_CONST9 17 (108)
91 LOAD_CONST2 7 (127)
94 LOAD_CONST11 8 (45)
97 LOAD_CONST2 18 (95)
100 LOAD_CONST12 11 (104)
103 LOAD_CONST2 19 (125)
106 LOAD_CONST16 15 (120)
109 LOAD_CONST2 20 (111)
112 LOAD_CONST14 21 (97)
115 LOAD_CONST2 22 (100)
118 LOAD_CONST15 23 (110)
121 BUILD_LIST 26
124 GET_ITER
125 CALL_FUNCTION 1
128 CALL_FUNCTION 1
131 CALL_FUNCTION 1
134 POP_TOP
>> 135 LOAD_CONST 0 (None)
138 RETURN_VALUE
================================================================================
22 0 LOAD_FAST 0 (.0)
>> 3 FOR_ITER 21 (to 27)
6 LOAD_CONST16 1 (None)
9 LOAD_GLOBAL 0 (chr)
12 LOAD_FAST 1 (_)
15 LOAD_CONST 0 (13)
18 BINARY_XOR
19 CALL_FUNCTION 1
22 YIELD_VALUE
23 POP_TOP
24 JUMP_ABSOLUTE 3
>> 27 LOAD_CONST 1 (None)
30 RETURN_VALUE
Great, that definitely sounds like what we described earlier.
I need a decompiler dad
Now because we really like to hack things, I decided to patch a Python decompiler to support the opcodes defined in this challenge in order to fully decompile the codes we saw so far.
I won't bother you with how I managed to do it though ; long story short: it is built it on top of fupy.py which is a readable hackable Python 2.7 decompiler written by the awesome Guillaume Delugre -- Cheers to my mate @Myst3rie for telling about this project!
So here is decompiler.py working on the two code objects of the challenge:
PS D:\Codes\ql-chall-python-2014> python .\decompiler_ql_chall.py
PART1 ====================
Robert_Forsyth = 1
True = True + 1
PART2 ====================
if True != 3:
True = True - 1
else:
quarkslab.append(''.join(chr(_ ^ 13) for _ in [75, 98, 127, 45, 89, 101, 104, 45, 67, 104, 122, 45, 65, 120, 99, 108, 127, 45, 95, 104, 125, 120, 111, 97, 100, 110]))
Brilliant -- time to get a flag now :-). Here are the things we need to do:
- Set True to 2 (so that it's equal to 3 in the part 2)
- Declare a list named quarkslab
- Jump over the middle part of the function where it will run the bytecode you gave as argument (or give a valid marshaled string that won't crash the interpreter)
- Profit!
overclok@wildout:~/chall/ql-py$ /usr/bin/b7d8438de09fffb12e3950e7ad4970a4a998403bdf3763dd4178adf
Python 2.7.8+ (nvcs/newopcodes:a9bd62e4d5f2+, Sep 1 2014, 11:41:46)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> True = 2
>>> quarkslab = list()
>>> import do_not_run_me as v
>>> v.run_me("c\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00C\x00\x00\x00s\x04\x00\x00\x00d\x00\x00\x1B(\x01\x00\x00\x00N(\x00\x00\x00\x00(\x00\x00\x00\x00(\x00\x00\x00\x00(\x00\x00\x00\x00s\x07\x00\x00\x00rstdinrt\x01\x00\x00\x00a\x01\x00\x00\x00s\x02\x00\x00\x00\x00\x01")
>>> quarkslab
['For The New Lunar Republic']
Conclusion
This was definitely entertaining, so thanks to Serge and Quarkslab for putting this challenge together! I feel like it would have been cooler to force people to write a disassembler or/and a decompiler to study the code of run_me though ; because as I mentioned at the very beginning of the article you don't really need any tool to guess/know roughly where the flag is, and how to get it. I still did write all those little scripts because it was fun and cool that's all!
Anyway, the codes I talked about are available on my github as usual if you want to have a look at them. You can also have look at wildfire.py if you like weird/wild/whatever Python beasts!
That's all for today guys, I hope it wasn't too long and that you did enjoy the read.
By the way, we still think it would be cool to have more people posting on that blog, so if you are interested feel free to contact us!